Editor’s Note: This blog post was written in collaboration with Airbyte. Their new vector database destination makes it really easy for data to retrieve relevant context for question answering use cases via LangChain. We're seeing more and more teams seek ways to integrate diverse data sources–and keep them up-to-date automatically–and this is a fantastic way to do it!
Aside from the specific use case highlighted here, we're also very excited about this integration in general. It combines the hundreds of sources in AirByte with their robust scheduling and orchestration framework, and leverages the advanced transformation logic in LangChain along with LangChain's 50+ embedding provider integrations and 50+ vectorstore integrations.
Learn how to build a connector development support bot for Slack that knows all your APIs, open feature requests and previous Slack conversations by heart
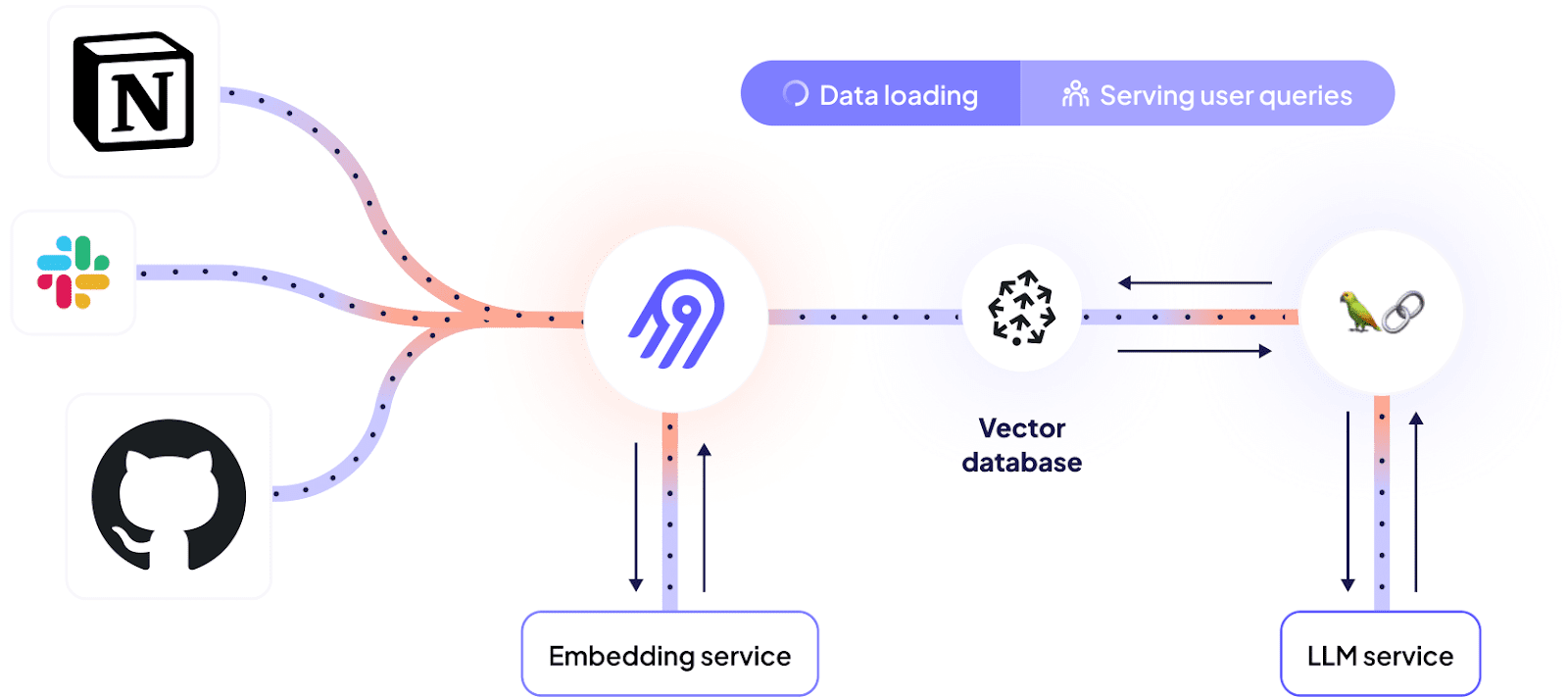
In a previous article, we explained how Dagster and Airbyte can be leveraged to power LLM-supported use cases. Our newly introduced vector database destination makes this even easier as it removes the need to orchestrate chunking and embedding manually - instead the sources can be directly connected to the vector database through an Airbyte connection.
This tutorial walks you through a real-world use case of how to leverage vector databases and LLMs to make sense out of your unstructured data. By the end of this, you will:
- Know how to extract unstructured data from a variety of sources using Airbyte
- Know how to use Airbyte to efficiently load data into a vector database, preparing the data for LLM usage along the way
- Know how to integrate a vector database into your LLM to ask questions about your proprietary data
What we will build
To better illustrate how this can look in practice, let’s use something that’s relevant for Airbyte itself.
Airbyte is a highly extensible system that allows users to develop their own connectors to extract data from any API or internal systems. Helpful information for connector developers can be found in different places:
- The official connector development documentation website
- Github issues documenting existing feature requests, known bugs and work in progress
- The community Slack help channel
This article describes how to tie together all of these diverse sources to offer a single chat interface to access information about connector development - a bot that can answer questions in plain english about the code base, documentation and reference previous conversations:
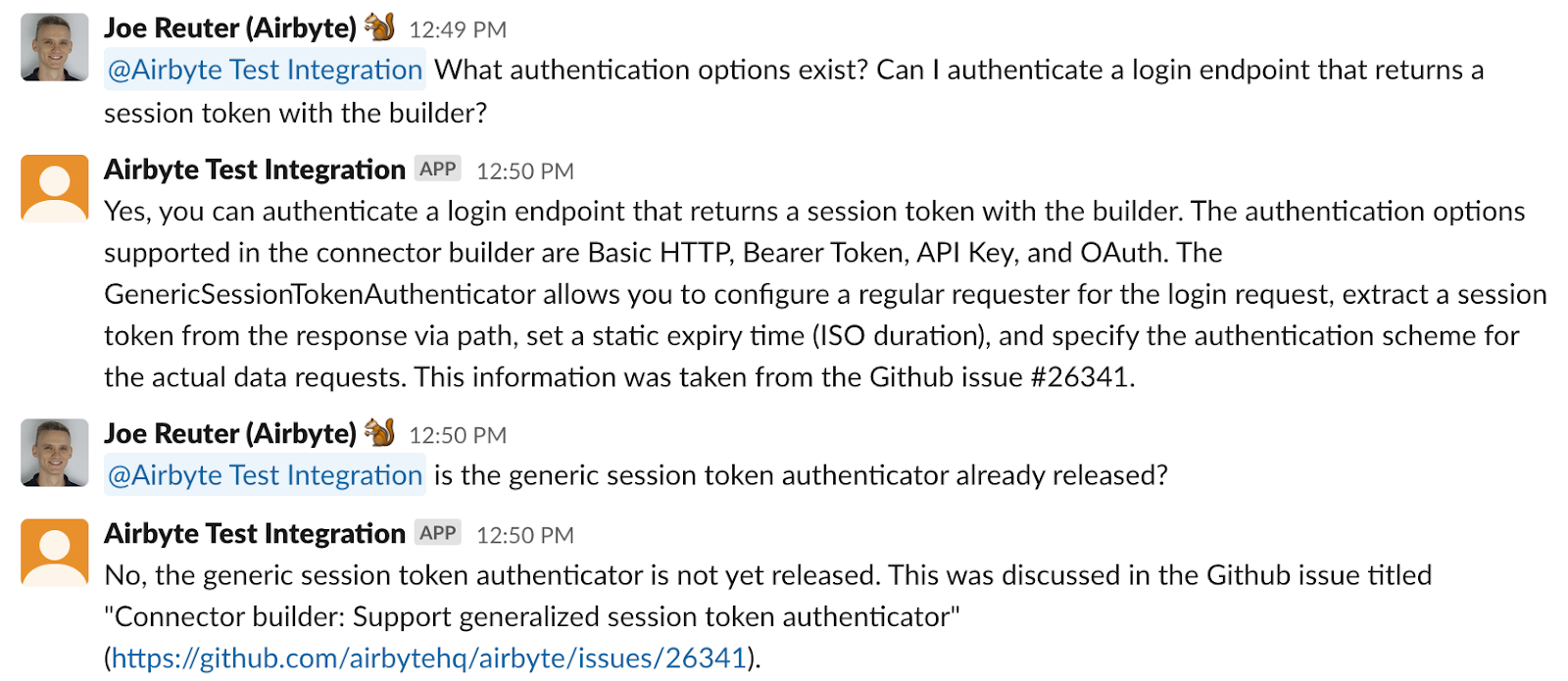
In these examples, information from the documentation website and existing Github issues is combined in a single answer.
Prerequisites
For following through the whole process, you will need the following accounts. However, you can also work with your own custom sources and use a local vector store to avoid all but the OpenAI account:
- Source-specific accounts
- Apify account
- Github account
- Slack account
- Destination-specific accounts
- OpenAI account
- Pinecone account
- Airbyte instance (local or cloud)
Step 1 - Fetch Github issues
Airbyte’s feature and bug tracking is handled by the Github issue tracker of the Airbyte open source repository. These issues contain important information people need to look up regularly.
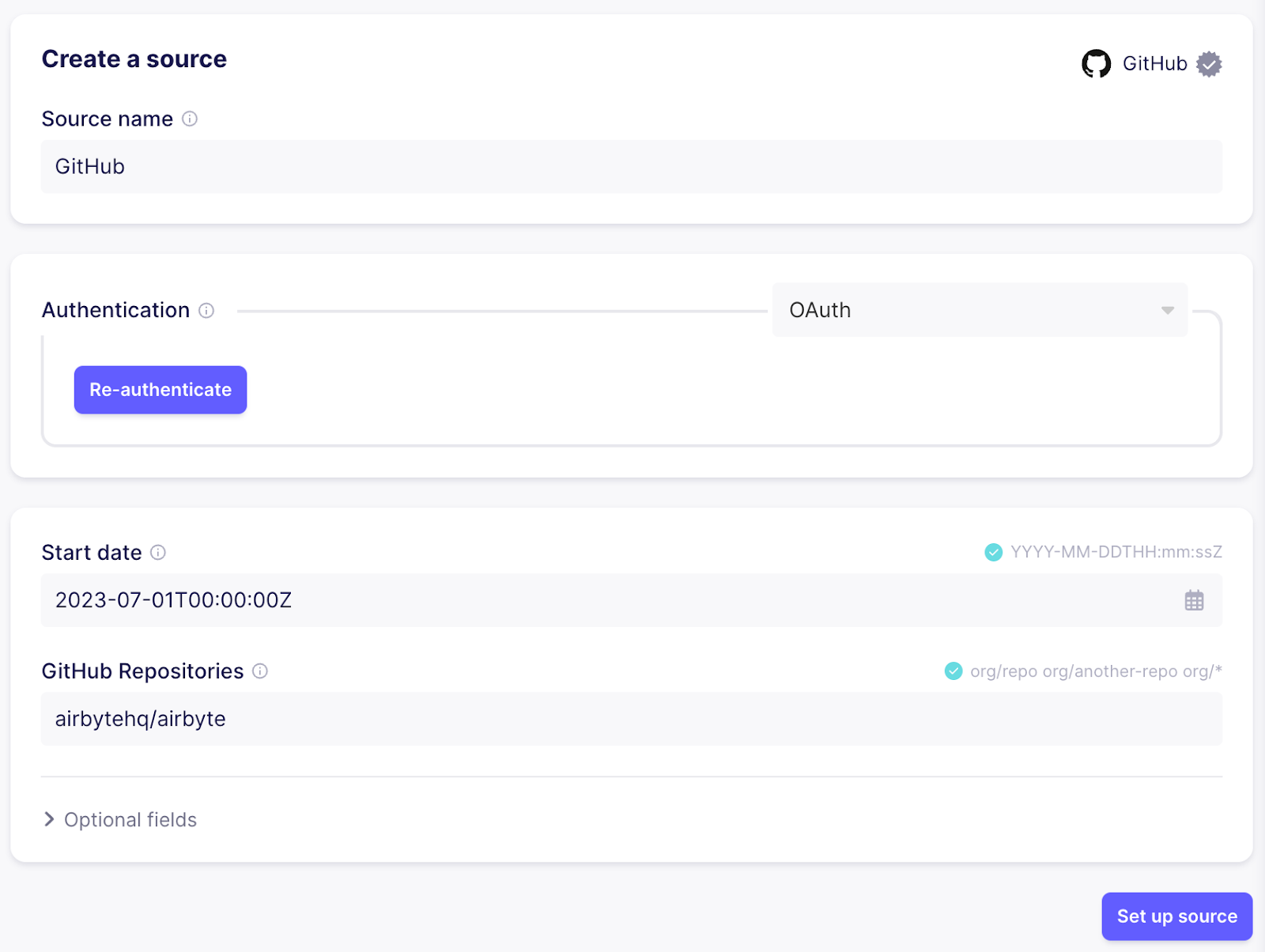
To fetch Github issues, create a new source using the Github connector.
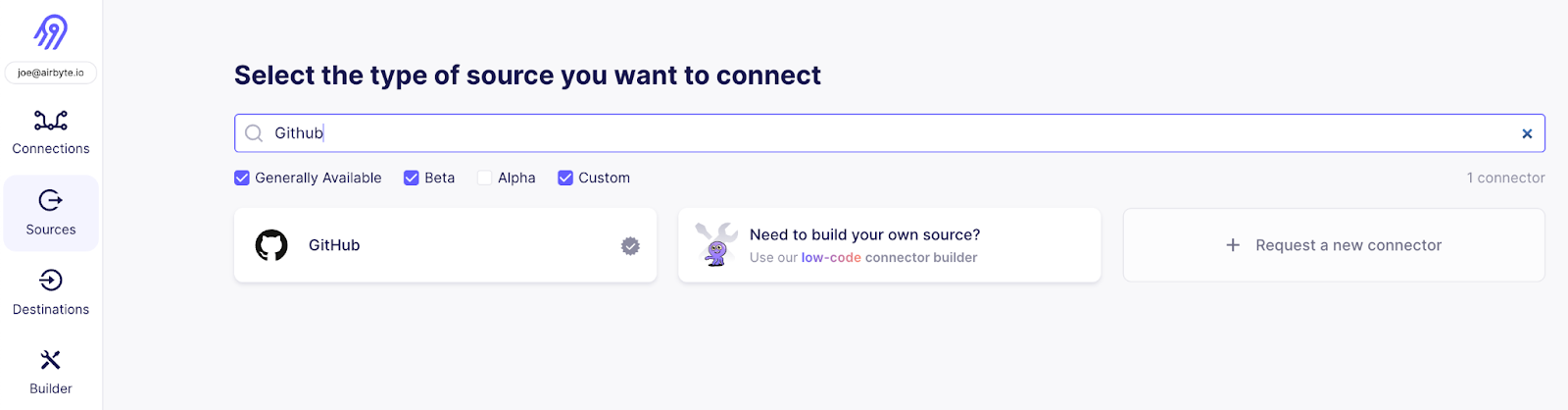
If you are using Airbyte Cloud , you can easily authenticate using the “Authenticate your GitHub account”, otherwise follow the instructions in the documentation on the right side of how to set up a personal access token in the Github UI.
Next, configure a cutoff date for issues and specify the repositories that should be synced. In this case I’m going with “2023-07-01T00:00:00Z” and “airbytehq/airbyte” to sync recent issues from the main Airbyte repository:
Step 2 - Load into vector database
Now we have our first source ready, but Airbyte doesn’t know yet where to put the data. The next step is to configure the destination. To do so, pick the “Pinecone” connector. There is some preprocessing that Airbyte is doing for you so that the data is vector ready:
- Separating text and metadata fields and splitting up records into multiple documents to keep each document focused on a single topic and to make sure the text fits into the context window of the LLM that’s going to be used for question answering
- Embedding the text of every document using the configured embedding service, turning the text into a vector to do similarity search on
- Indexing the documents into the vector database (uploading the vector from the embedding service along with the metadata object)
Besides Pinecone, Airbyte supports loading data into Weaviate, Milvus, Qdrant and Chroma.
For using Pinecone, sign up for a free trial account and create an index using a starter pod. Set the dimensions to 1536 as that’s the size of the OpenAI embeddings we will be using
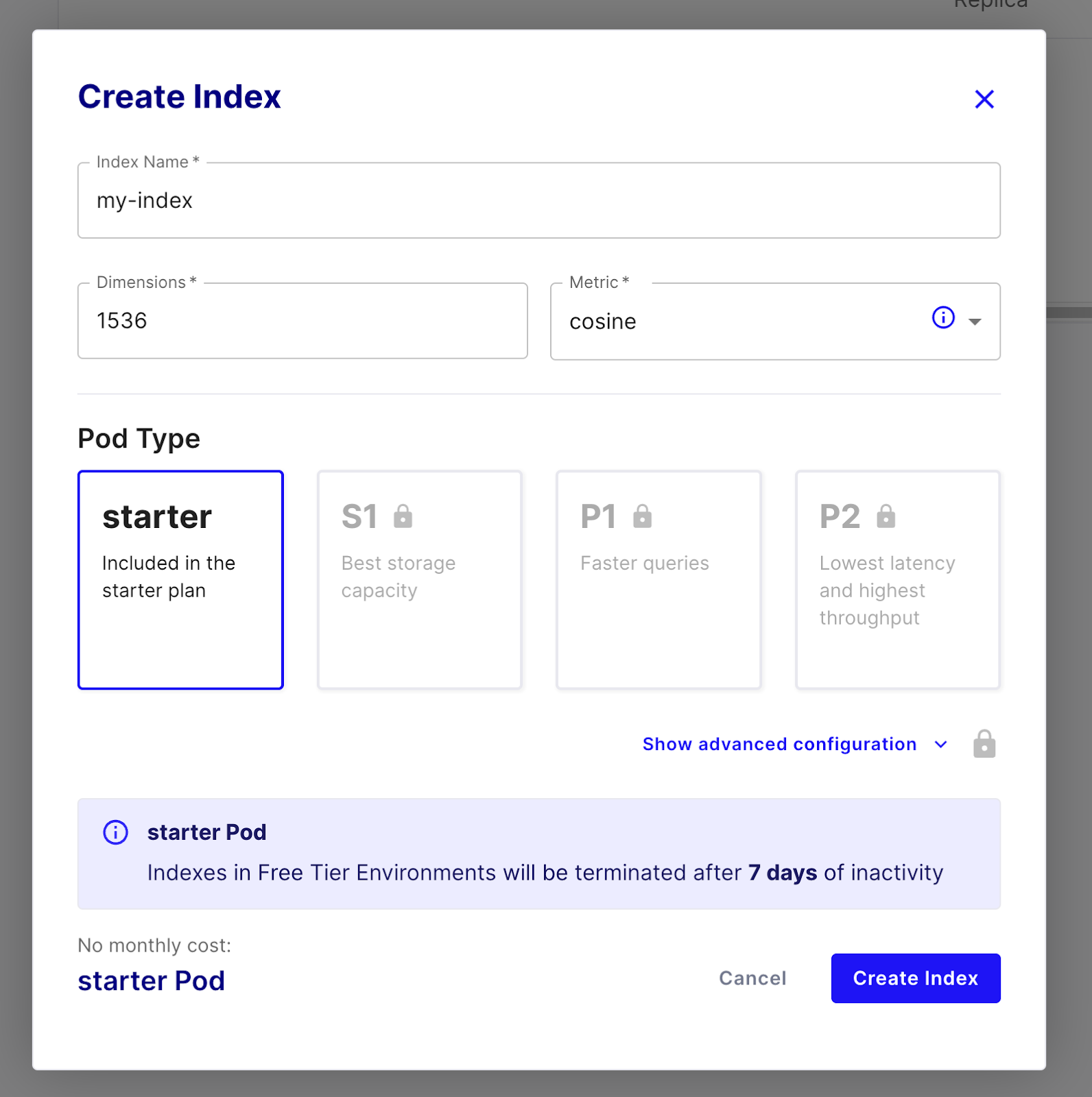
Once the index is ready, configure the vector database destination in Airbyte:
- Set chunk size to 1000 (the size refers to number of tokens, not characters, so this is roughly 4KB of text. The best chunking is dependent on the data you are dealing with)
- Configure the records fields to treat as text fields which will be embedded. All other fields will be handled as metadata. For now, set it “title” and “body” as these are the relevant feels in the issue stream of the Github source
- Set your OpenAI api key for powering the embedding service. You can find your API key in the API keys section of the platform.openai.com/account page
- For the indexing step, copy over index, environment and api key from the Pinecone UI. You can find the API key and the environment in the “API Keys” section in the UI


Step 3 - Create a connection
Once the destination is set up successfully, set up a connection from the Github source to the vector database destination. In the configuration flow, pick the existing source and destination. When configuring the connection, make sure to only use the “issues” stream, as this is the one we are interested in.
Side note: Airbyte allows to make this sync more efficient in a production environment:
- To keep the metadata focused, you can click on the stream name to select the individual fields you want to sync. For example if the “assignee” or the “milestone” field is never relevant to you, you can uncheck it and it won’t be synced to the destination.
- The sync mode can be used to sync issues incrementally while deduplicating the records in the vector database so no stale data will show up in searches
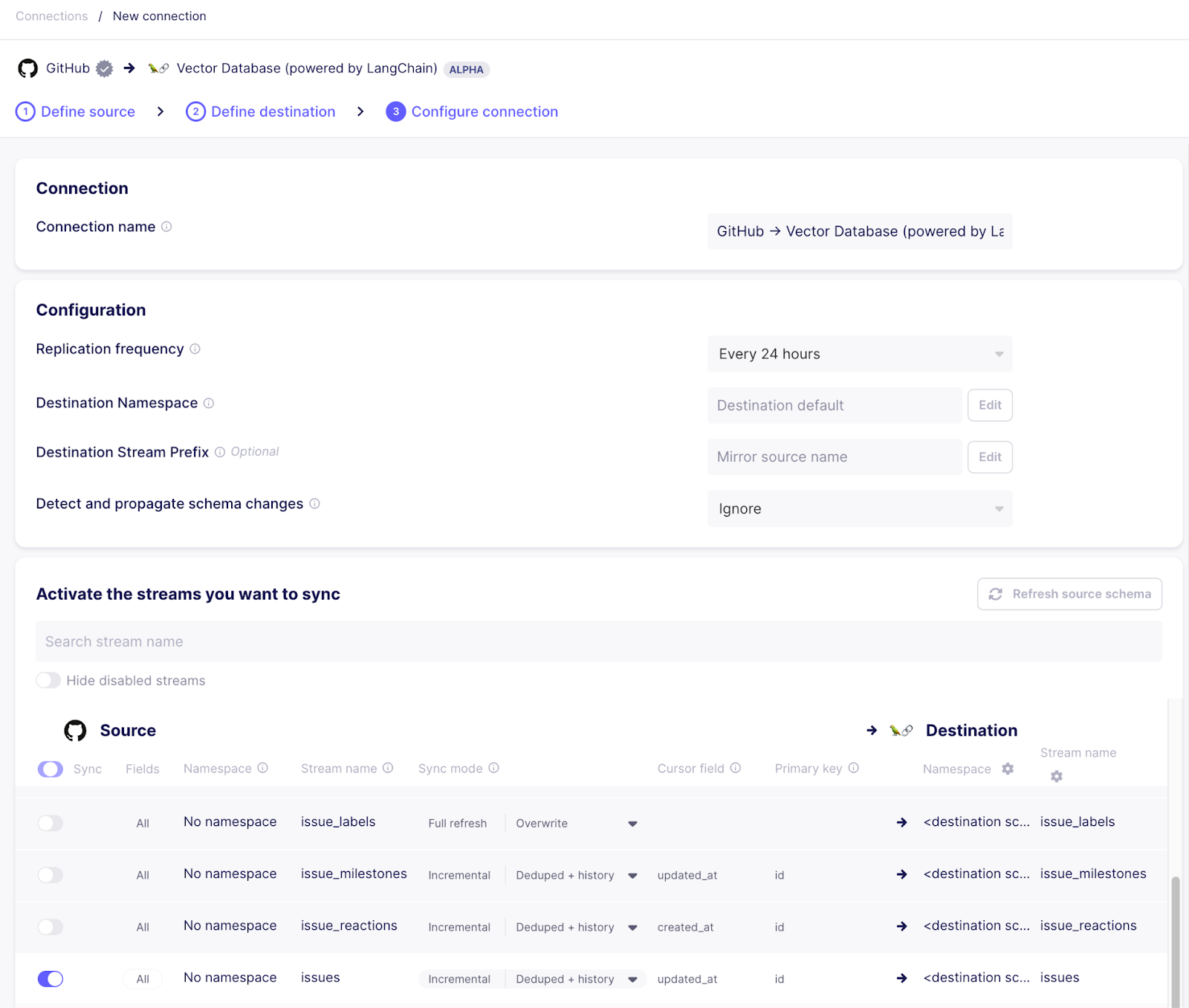
If everything went well, there should be a connection now syncing data from Github to Pinecone via the vector store destination. Give the sync a few minutes to run. Once the first run has completed, you can check the Pinecone index management page to see a bunch of indexed vectors ready to be queried.
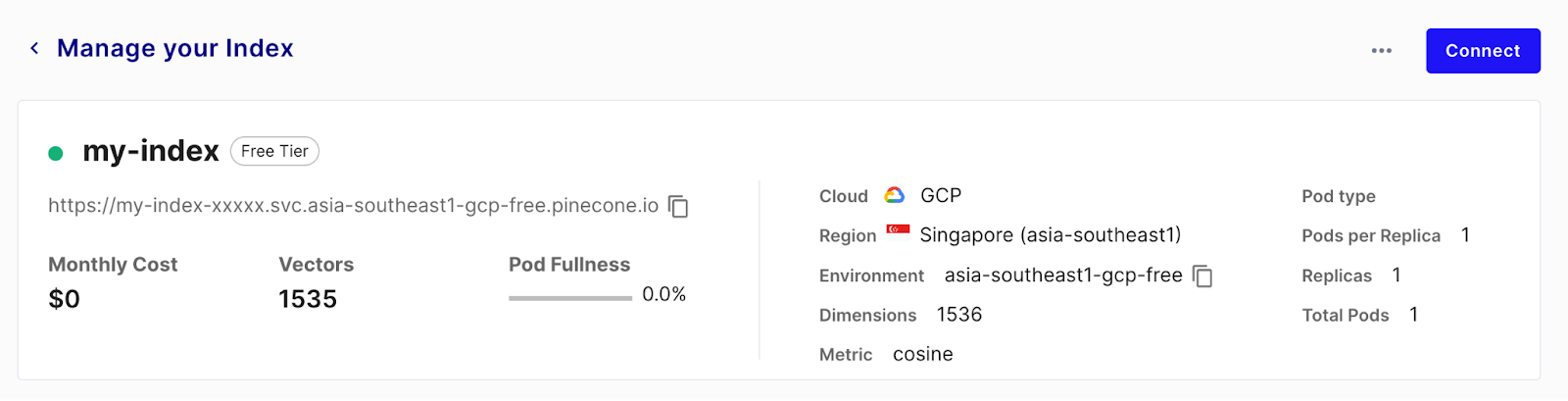
Each vector is associated with a metadata object that’s filled with the fields that were not mentioned as “text fields” in the destination configuration. These fields will be retrieved along with the embedded text and can be leveraged by our chatbot in later sections. This is how a vector with metadata looks like when retrieved from Pinecone:
{
"id": "599d75c8-517c-4f37-88df-ff16576bd607",
"values": [0.0076571689, ..., 0.0138477711],
"metadata": {
"_ab_stream": "issues",
"_ab_record_id": 1556650122,
"author_association": "CONTRIBUTOR",
"comments": 3,
"created_at": "2023-01-25T13:21:50Z",
// ...
"text": "...The acceptance-test-config.yml file is in a legacy format. Please migrate to the latest format...",
"updated_at": "2023-07-17T09:20:56Z",
}
}On subsequent runs, Airbyte will only re-embed and update the vectors for the issues that changed since the last sync - this will speed up subsequent runs while making sure your data is always up-to-date and available.
Step 4 - Chat interface
The data is ready, now let’s wire it up with our LLM to answer questions in natural language. As we already used OpenAI for the embedding, the easiest approach is to use it as well for the question answering.
We will use Langchain as an orchestration framework to tie all the bits together.
First, install a few pip packages locally:
pip install pinecone-client langchain openaiThe basic functionality here works the following way:
- User asks a question
- The question is embedded using the same model used for generating the vectors in the vector database (OpenAI in this case)
- The question vector is sent to the vector database and documents with similar vectors are returned - as the vectors represent the meaning of the text, the question and the answer to the question will have very similar vectors and relevant documents will be returned
- The text of all documents with the relevant metadata are put together into a single string and sent to the LLM together with the question the user asked and the instruction to answer the user’s question based on the provided context
- The LLM answers the question based on the provided context
- The answer is presented to the user
This flow is often referred to as retrieval augmented generation. The RetrievalQA class from the Langchain framework already implements the basic interaction. The simplest version of our question answering bot only has to provide the vector store and the used LLM:
# chatbot.py
import os
import pinecone
from langchain.chains import RetrievalQA
from langchain.embeddings import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.vectorstores import Pinecone
embeddings = OpenAIEmbeddings()
pinecone.init(api_key=os.environ["PINECONE_KEY"], environment=os.environ["PINECONE_ENV"])
index = pinecone.Index(os.environ["PINECONE_INDEX"])
vector_store = Pinecone(index, embeddings.embed_query, "text")
qa = RetrievalQA.from_chain_type(llm=OpenAI(temperature=0), chain_type="stuff", retriever=vector_store.as_retriever())
print("Connector development help bot. What do you want to know?")
while True:
query = input("")
answer = qa.run(query)
print(answer)
print("\nWhat else can I help you with:")To run this script, you need to set OpenAI and Pinecone credentials as environment variables:
export OPENAI_API_KEY=...
export PINECONE_KEY=...
export PINECONE_ENV=...
export PINECONE_INDEX=...
python chatbot.pyThis works in general, but it has some limitations. By default, only the text fields are passed into the prompt of the LLM, so it doesn’t know what the context of a text is and it also can’t give a reference back to where it found its information:
Connector development help bot. What do you want to know?
> Can you give me information about how to authenticate via a login endpoint that returns a session token?
Yes, the GenericSessionTokenAuthenticator should be supported in the UI[...]From here, there’s lots of fine tuning to do to optimize our chat bot. For example we can improve the prompt to contain more information based on the metadata fields and be more specific for our use case:
prompt_template = """You are a question-answering bot operating on Github issues and documentation pages for a product called connector builder. The documentation pages document what can be done, the issues document future plans and bugs. Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer. Always state were you got this information from (and the github issue number if applicable).
If the answer is based on a Github issue that's not closed yet, add 'This issue is not closed yet - the feature might not be shipped yet' to the answer.
{context}
Question: {question}
Helpful Answer:"""
prompt = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
class ConnectorDevelopmentPrompt(PromptTemplate):
def format_document(doc: Document, prompt: PromptTemplate) -> str:
if doc.metadata["_ab_stream"] == "issues":
return f"Excerpt from Github issue: {doc.page_content}, issue number: {doc.metadata['number']}, issue state: {doc.metadata['state']}"
else:
return super().format_document(doc, prompt)
document_prompt = ConnectorDevelopmentPrompt(input_variables=["page_content"], template="{page_content}")
qa = RetrievalQA.from_chain_type(llm=OpenAI(temperature=0), chain_type="stuff", retriever=vector_store.as_retriever(), chain_type_kwargs={"prompt": prompt, "document_prompt": document_prompt})The full script also be found on Github
This revised version of the RetrievalQA chain customizes the prompts that are sent to the LLM after the context has been retrieved:
- The basic prompt template sets the broader context what this question is about (previously the LLM had to guess from the documents)
- It also changes the way documents are added to the prompt - by default, only the text is added, but the ConnectorDevelopmentPrompt implementation sets the context where the data is coming from and also adds relevant metadata to the prompt so the LLM can base its answer on more than just the text
Connector development help bot. What do you want to know?
> Can you give me information about how to authenticate via a login endpoint that returns a session token?
You can use the GenericSessionTokenAuthenticator to authenticate via a login endpoint that returns a session token. This is documented in the Connector Builder documentation with an example of how the request flow functions (e.g. metabase). This issue is not closed yet - the feature might not be shipped yet (Github issue #26341).
Step 5 - Put it on Slack
So far this helper can only be used locally. However, using the python slack sdk it’s easy to turn this into a Slack bot itself.
To do so, we need to set up a Slack “App” first. Go to https://api.slack.com/apps and create a new app based on the manifest here (this saves you some work configuring permissions by hand). After you set up your app, install it to the workspace you want to integrate with. This will generate a “Bot User OAuth Access Token” you need to note down. Afterwards, go to the “Basic information” page of your app, scroll down to “App-Level Tokens” and create a new token. Note down this “app level token” as well.
Within the regular Slack client, your app can be added to a slack channel by clicking the channel name and going to the “Integrations” tab:
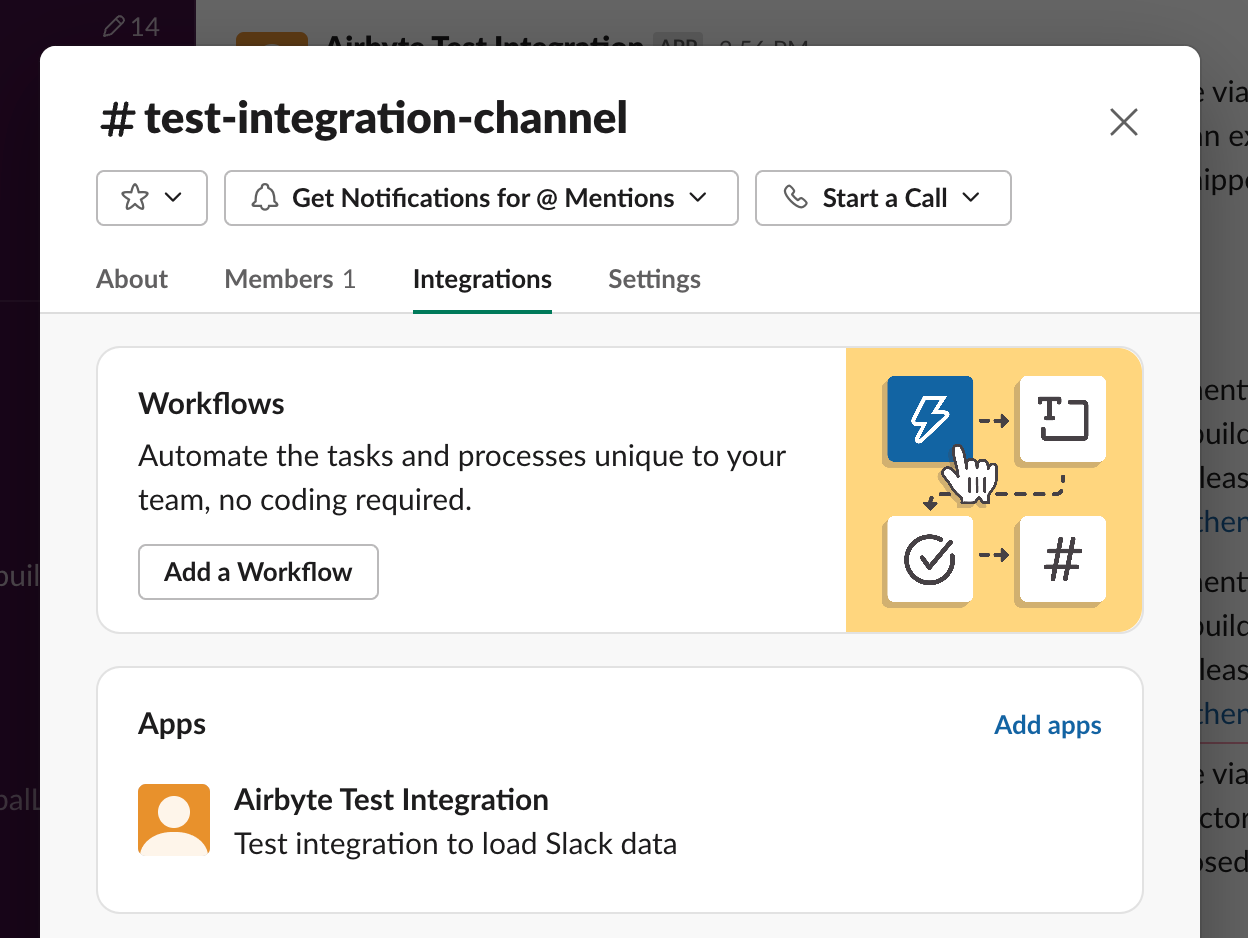
After this, your Slack app is ready to receive pings from users to answer questions - the next step is to call Slack from within python code, so we need to install the python client library:
pip install slack_sdkAfterwards, we can extend our existing chatbot script with a Slack integration:
from slack_sdk import WebClient
from slack_sdk.socket_mode import SocketModeClient
from slack_sdk.socket_mode.request import SocketModeRequest
from slack_sdk.socket_mode.response import SocketModeResponse
slack_web_client = WebClient(token=os.environ["SLACK_BOT_TOKEN"])
handled_messages = {}
def process(client: SocketModeClient, socket_mode_request: SocketModeRequest):
if socket_mode_request.type == "events_api":
event = socket_mode_request.payload.get("event", {})
client_msg_id = event.get("client_msg_id")
if event.get("type") == "app_mention" and not handled_messages.get(client_msg_id):
handled_messages[client_msg_id] = True
channel_id = event.get("channel")
text = event.get("text")
result = qa.answer(text)
slack_web_client.chat_postMessage(channel=channel_id, text=result)
return SocketModeResponse(envelope_id=socket_mode_request.envelope_id)
socket_mode_client = SocketModeClient(
app_token=os.environ["SLACK_APP_TOKEN"],
web_client=slack_web_client
)
socket_mode_client.socket_mode_request_listeners.append(process)
socket_mode_client.connect()
print("listening")
from threading import Event
Event().wait()The full script also be found on Github
To run the script, the environment variables for the slack bot token and app token need to be added as environment variables as well:
export SLACK_BOT_TOKEN=...
export SLACK_APP_TOKEN=...
python chatbot.pyRunning this, you should be able to ping the development bot application in the channel you added it to like a user and it will respond to questions by running the RetrievalQA chain that loads relevant context from the vector database and uses an LLM to formulate a nice answer:

All the code can also be found on Github
Step 6 - Additional data source: Scrape documentation website
Github issues are helpful, but there is more information we want our development bot to know.
The documentation page for connector development is a very important source of information to answer questions, so it definitely needs to be included. The easiest way to make sure the bot has the same information as what’s published, is to scrape the website. For this case, we are going to use the Apify service to take care of the scraping and turning the website into a nicely structured dataset. This dataset can be extracted using the Airbyte Apify Dataset source connector.
First, log into Apify and navigate to the store. Choose the “Web Scraper” actor as a basis - it already implements most of the functionality we need

Next, create a new task and configure it to scrape all pages of the documentation, extracting the page title and all of the content:
- Set Start URLs to https://docs.airbyte.com/connector-development/connector-builder-ui/overview/ , the intro page of the documentation linking to other pages
- Set Link selector to a[href] to follow all links from every page
- Set Glob Patterns to https://docs.airbyte.com/connector-development/connector-builder-ui/* to limit the scraper to stick to the documentation and not crawl the whole internet
- Configure the Page function to extract the page title and the content - in this case the content element can be found using the CSS class name
async function pageFunction(context) {
const $ = context.jQuery;
const pageTitle = $('title').first().text();
const content = $('.markdown').first().text();
return {
url: context.request.url,
pageTitle,
content
};
}Running this actor will complete quickly and give us a nicely consumable dataset with a column for the page title and the content:
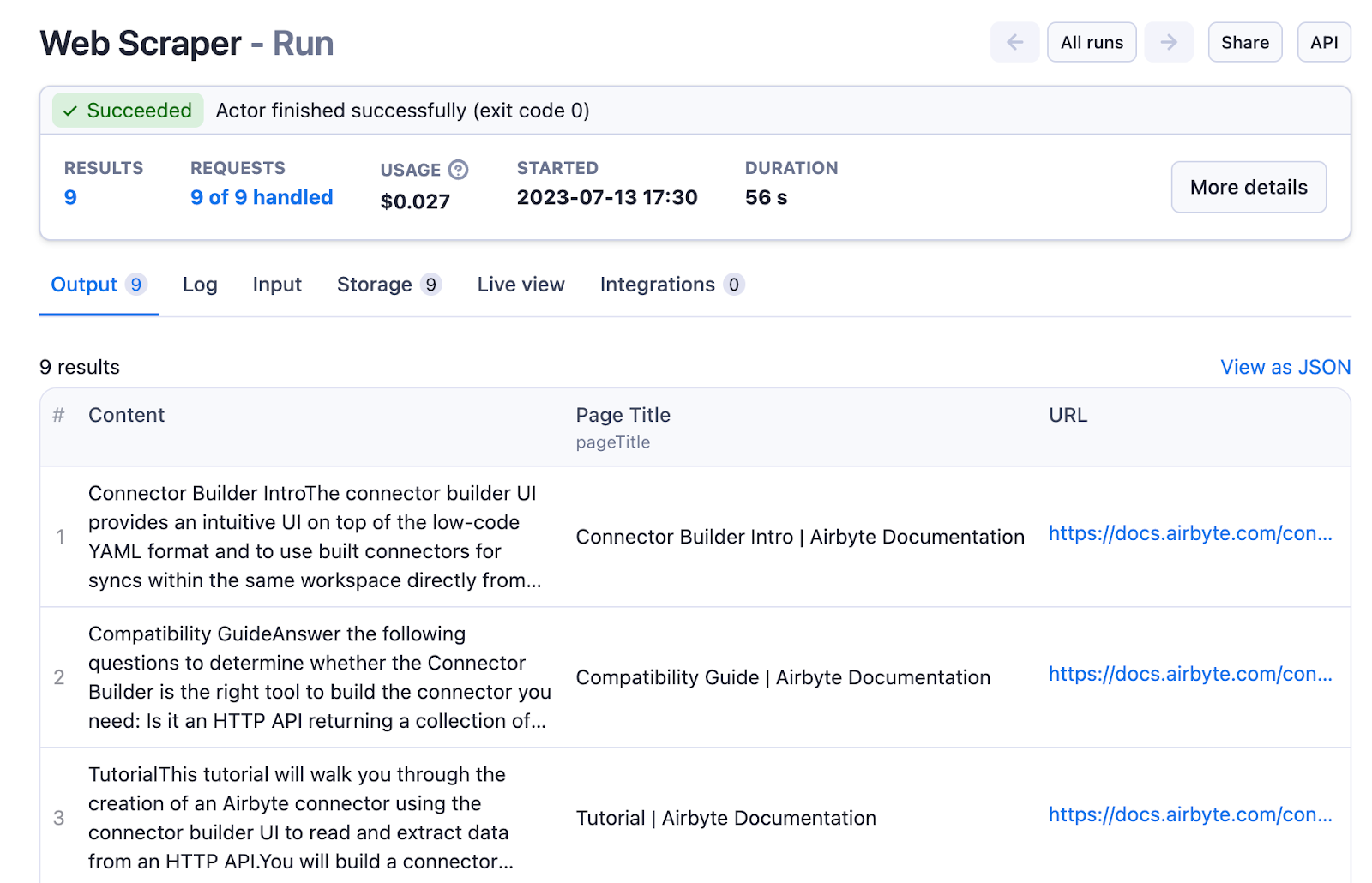
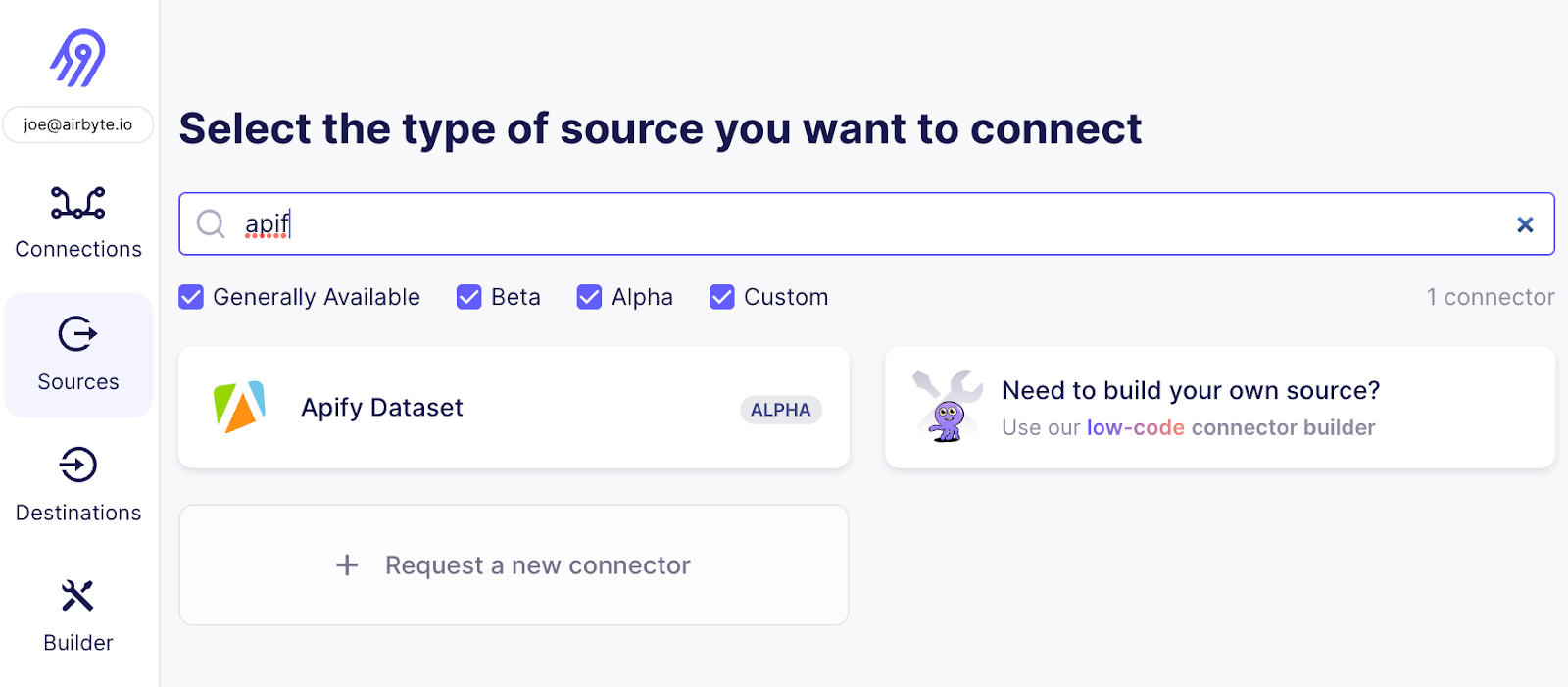
Now it’s time to connect Airbyte to the Apify data set - go to the Airbyte web UI and add your second Source - pick “Apify Dataset”
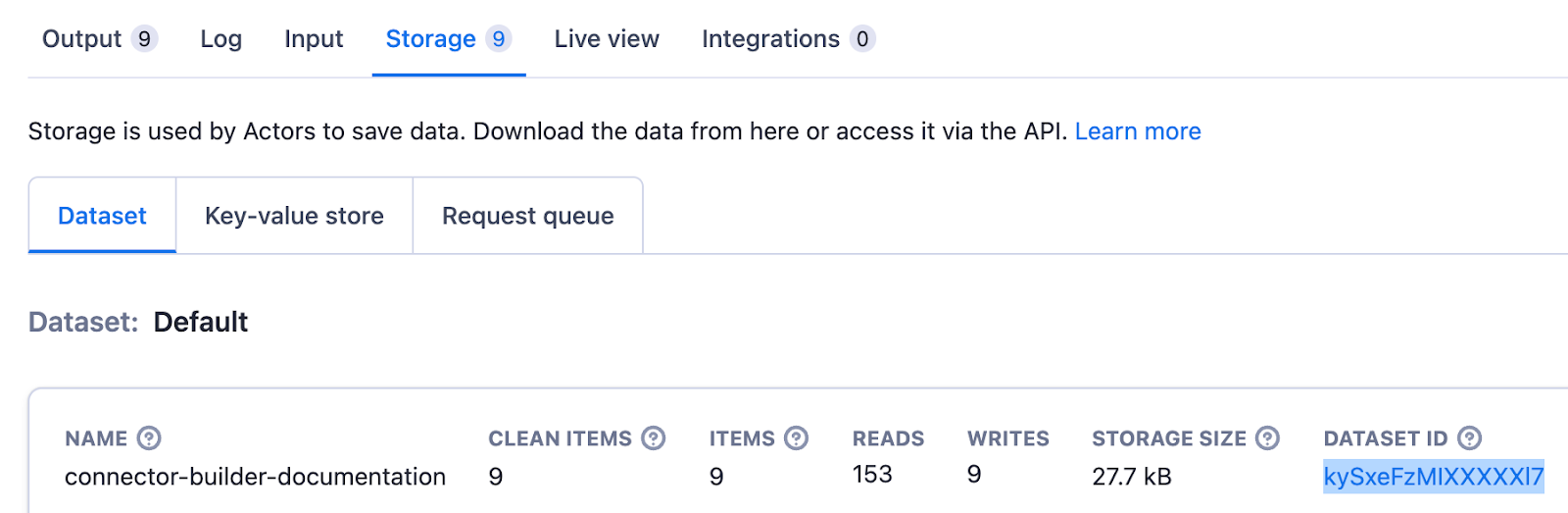
To set up the Source, you only need to copy the dataset ID that’s shown in the “Storage” tap of the “Run” in the Apify UI
Once the source is set up, follow the same steps as for the Github source to set up a connection moving data from the Apify dataset to the vector store. As the relevant text content is sitting in different fields, you also need to update the vector store destination - add data.pageTitle and data.content to the “text fields” of the destination and save.
Step 7 - Additional data source: Fetch Slack messages
Another valuable source of information relevant to connector development are Slack messages from the public help channel. These can be loaded in a very similar fashion. Create a new source using the Slack connector. When using cloud, you can authenticate using the “Authenticate your Slack account” button for simple setup, otherwise follow the instructions in the documentation on the right hand side how to create a Slack “App” with the required permissions and add it to your workspace. To avoid fetching messages from all channels, set the channel name filter to the correct channel.
As for Apify and Github, a new connection needs to be created to move data from Slack to Pinecone. Also add text to the “text fields” of the destination to make sure the relevant data gets embedded properly so similarity searches will yield the right results.
If everything went well, there should be three connections now, all syncing data from their respective sources to the centralized vector store destination using a Pinecone index.
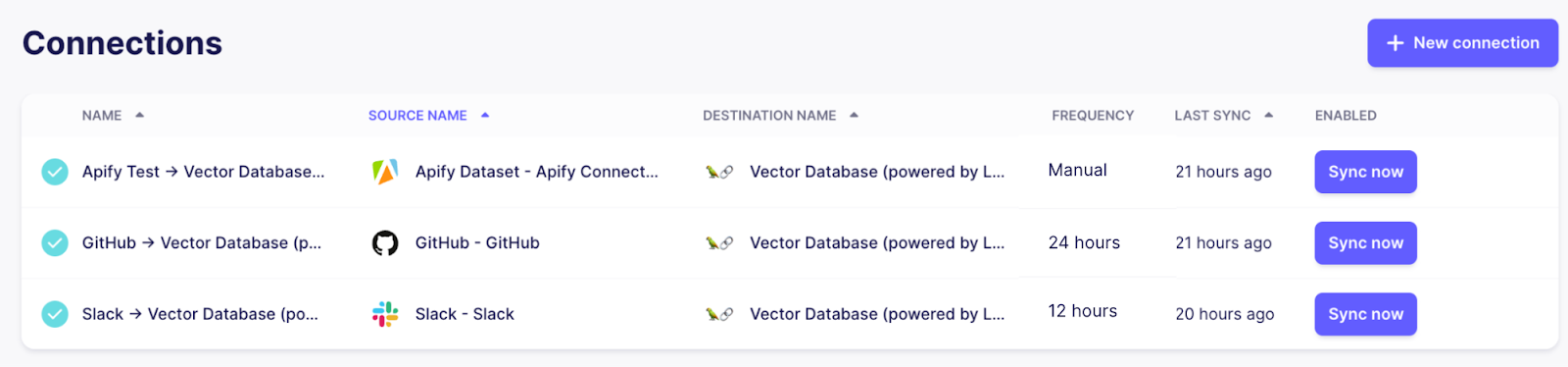
By adjusting the frequency of the connections, you can control how often Airbyte will rerun the connection to make sure the knowledge base of our chat bot stays up to date. As Github and Slack are frequently updated and support efficient incremental updates, it makes sense to set them to a daily frequency or higher. The documentation pages don’t change as often, so they can be kept at a lower frequency or even just be triggered on demand when there are changes.
As we have more sources now, let’s improve our prompt to make sure the LLM has all necessary information to formulate a good answer:
class ContextualRetriever(VectorStoreRetriever):
def _get_relevant_documents(self, query: str, *, run_manager):
docs = super()._get_relevant_documents(query, run_manager=run_manager)
return [self.format_doc(doc) for doc in docs]
def format_doc(self, doc: Document) -> Document:
if doc.metadata["_ab_stream"] == "item_collection":
doc.page_content = f"Excerpt from documentation page: {doc.page_content}"
elif doc.metadata["_ab_stream"] == "issues":
doc.page_content = f"Excerpt from Github issue: {doc.page_content}, issue number: {int(doc.metadata['number']):d}, issue state: {doc.metadata['state']}"
elif doc.metadata["_ab_stream"] == "threads" or doc.metadata["_ab_stream"] == "channel_messages":
doc.page_content = f"Excerpt from Slack thread: {doc.page_content}"
return docBy default the RetrievalQA chain retrieves the top 5 matching documents, so if it’s applicable the answer will be based on multiple sources at the same time:
Connector development help bot. What do you want to know?
> What different authentication methods are supported by the builder? Can I authenticate a login endpoint that returns a session token?
The authentication methods supported by the builder are Basic HTTP, Bearer Token, API Key, and OAuth. The builder does not currently support authenticating a login endpoint that returns a session token, but this feature is planned and can be tracked in the Github issue #26341. This issue is not closed yet - the feature might not be shipped yet.The first sentence about Basic HTTP, Bearer Token, API Key and OAuth is retrieved from the documentation page about authentication, while the second sentence is referring to the same Github issue as before.
Wrapping up
We covered a lot of ground here - stepping back a bit, we accomplished the following parts:
- Set up a pipeline that loads unstructured data from multiple sources into a vector database
- Implement an application that can answer plain text questions about the unstructured data in a general way
- Expose this application as a Slack bot
With data flowing through this system, Airbyte will make sure the data in your vector database will always be up-to-date while only syncing records that changed in the connected source, minimizing the load on embedding and vector database services while also providing an overview over the current state of running pipelines.
This setup isn’t using a single black box service that encapsulates all the details and leaves us with limited options for tweaking behavior and controlling data processing - instead it’s composed out of multiple components that be easily extended in various places:
- The large catalog of Airbyte sources and the connector builder for integrating specialized sources allow to easily load just about any data into a vector db using a single tool
- Langchain is very extensible and allows you to leverage LLMs in different ways beyond this simple application, including enriching data from other sources, keeping a chat history to be able to have full conversations and more
If you are interested in leveraging Airbyte to ship data to your LLM-based applications, take a moment to fill out our survey so we can make sure to prioritize the most important features.