Key Links
Motivation
Code generation and analysis are two of most important applications of LLMs, as shown by the ubiquity of products like GitHub co-pilot and popularity of projects like GPT-engineer. The recent AlphaCodium work showed that code generation can be improved by using a flow paradigm rather than a naive prompt:answer paradigm: answers can be iteratively constructed by (1) testing answers and (2) reflecting on the results of these tests in order to improve the solution.

We recently launched LangGraph to support flow engineering, giving the user the ability to represent flows as a graph. Inspired by the AlphaCodium and Reflexion work, we wanted to demonstrate that LangGraph can be used to implement code generation with the same types of cycles and decisions points as shown above.
Specifically we wanted to build and compare two different architectures:
- Code generation via prompting and context stuffing
- Code generation flow that involved checking and running the code, and then if there was some error passing it back to correct itself
This would attempt to answer: how much can these code checks improve performance of a code generation system?
The answer?
Problem
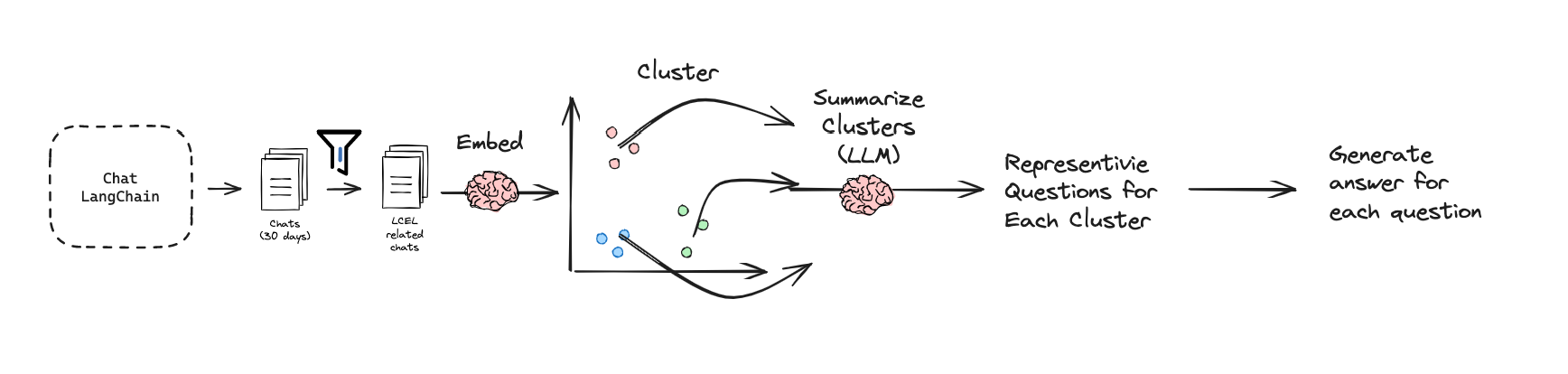
To demonstrate code generation on a narrow corpus of documentation, we chose a sub-set of LangChain docs focused on LangChain Expression Language (LCEL), which is both bounded (~60k token) and a topic of high interest. We mined 30 days of chat-langchain for LCEL related questions (code here). We filtered for those that mentioned LCEL, from >60k chats to ~500. We clustered the ~500 and had an LLM (GPT-4, 128k) summarize clusters to give us representative questions in each. We manually reviewed and generated a ground truth answer for each question (eval set of 20 questions here). We added this dataset to LangSmith.
Code generation with reflection using LangGraph
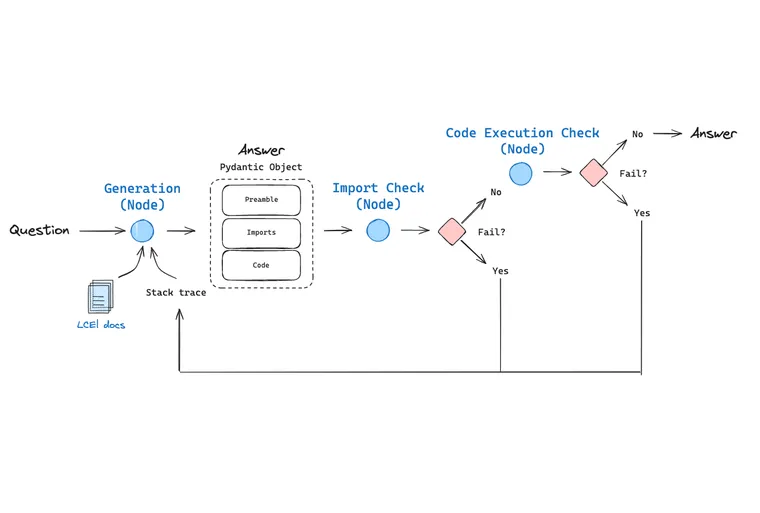
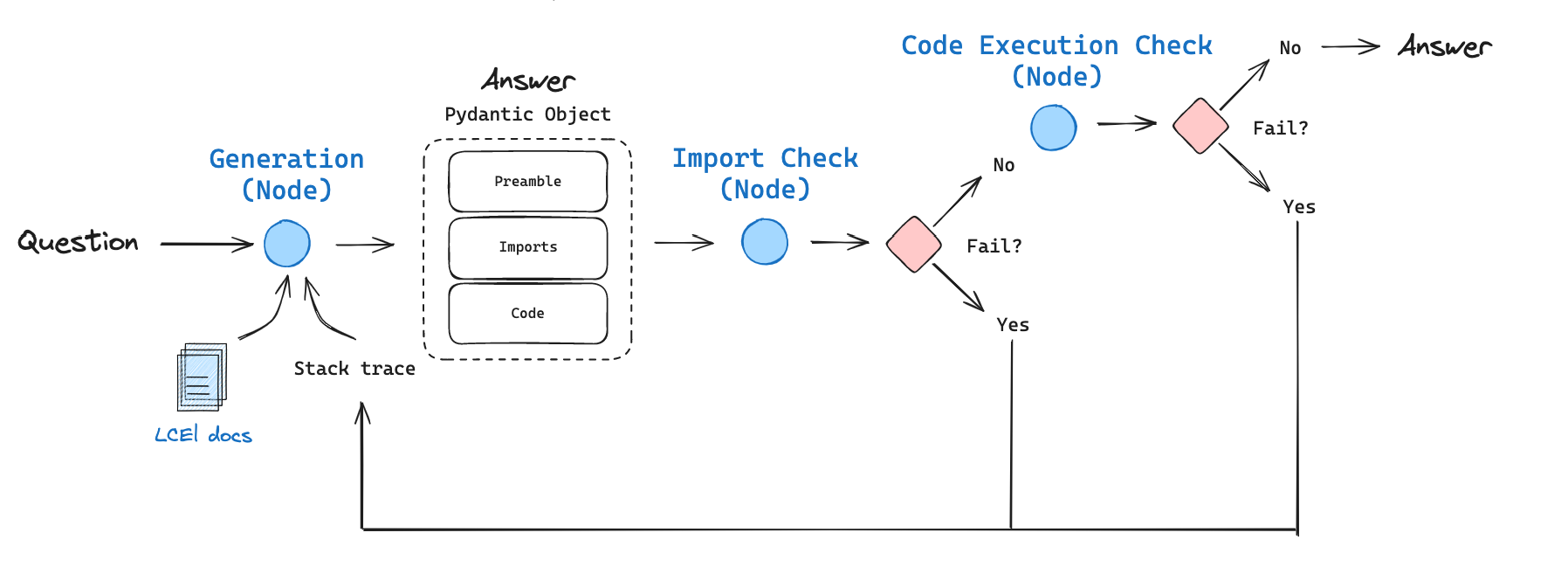
We implement a code generation flow with the following components:
- Inspired by recent trends in long-context LLMs, we context stuff the 60k token LCEL docs using GPT-4 with a 128k token context window. We pass a question about LCEL to our context-stuffed LCEL chain for initial answer generation.
- We use OpenAI tools to parse the output to a Pydantic object with three parts: (1) a preamble describing the problem, (2) the import block, (3) the code.
- We first check import execution, because we have found that hallucinations can creep into import statements during code generation.
- If the import check passes, we then check that the code itself can be executed. In the generation prompt, we instruct the LLM not to use pseudo-code or undefined variables in the code solution, which should yield executable code.
- Importantly, if either check fails, we pass back the stack trace along with the prior answer to the generation node to reflect We allow this to re-try 3 times (simply as a default value), but this can of course be extended as desired.
Evaluation with LangSmith
As a baseline, we implement context stuffing without LangGraph, which is the first node in our graph without any of the checks or feedback: we context stuff the 60k token LCEL docs using GPT-4 with a 128k token context window. We pass a question about LCEL to our context-stuffed LCEL chain for answer generation.
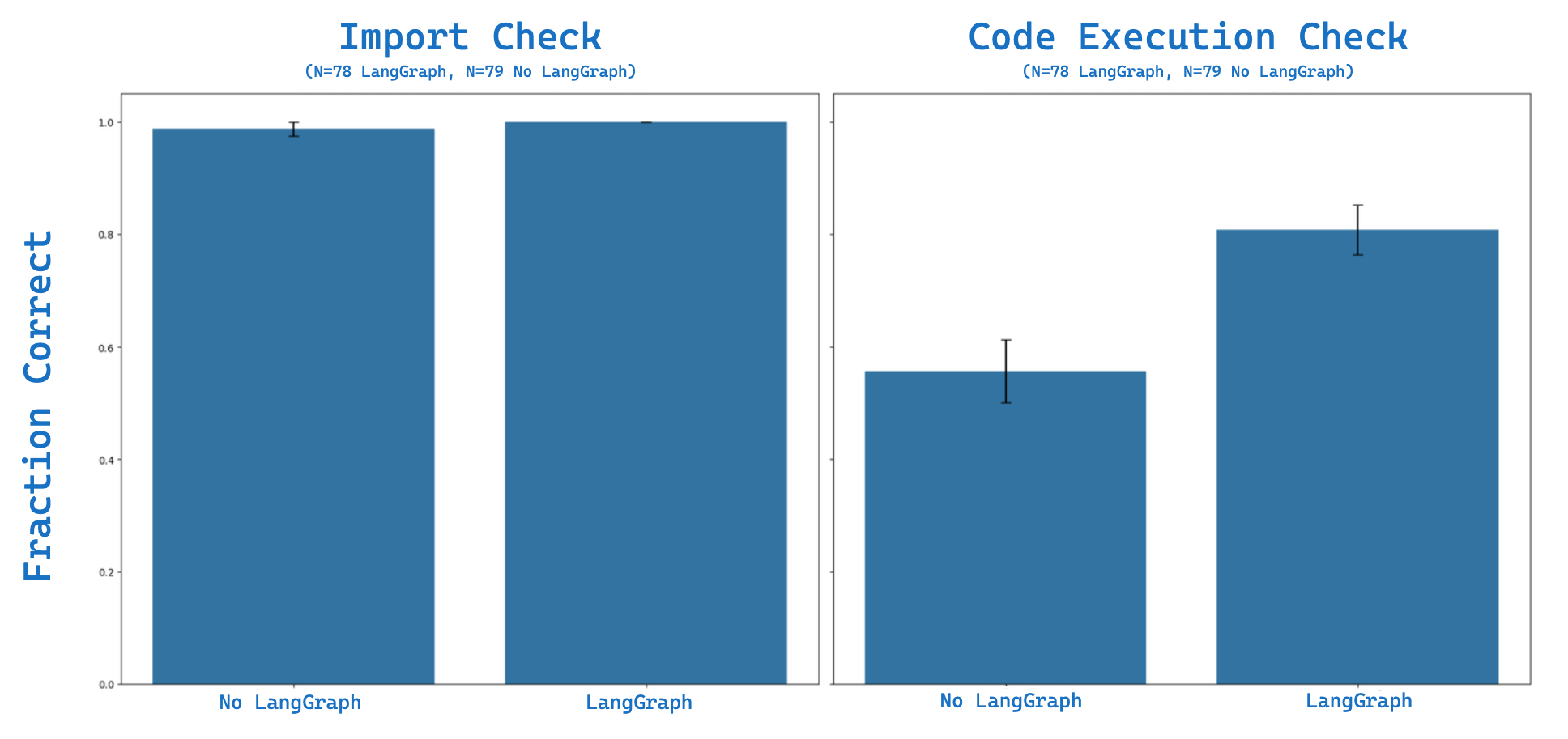
We implement LangSmith custom evaluators for both (1) import evaluation and (2) code execution. We run evaluation on context stuffing with our 20 question eval set four times. Here is our eval result. With context stuffing we see ~98% of the import tests are correct and ~55% of the code execution tests (N=79 successful trials). We use LangSmith to look at our failures: here is one example, which fails to see that the RunnableLambda function input will be a dict and thinks that it is a string: AttributeError: 'dict' object has no attribute 'upper'
We then tested context stuffing + LangGraph to (1) perform checks for errors like this in both imports and code execution and (2) reflect on any errors when performing updated answer generation. On the same eval set, we see 100% of the import tests are correct along with ~81% of the code execution tests (N=78 trials).
We can revisit the above failure to demonstrate why: the full trace shows that we do hit that same error here, in our second attempt at answering the question. We include this error in our reflection step in which both the prior solution and the resulting error are provided within the prompt for the final (correct) answer:
You previously tried to solve this problem.
...
--- Most recent run error ---
Execution error: 'dict' object has no attribute 'upper'
...
Please re-try to answer this.
...The final generation then correctly handles the input dict in the RunnableLambda function, bypassing the error observed in the context stuffing base case. Overall, adding this simple reflection step and re-try using LangGraph results in a substantial improvement on code execution, ~47% improvement:
Conclusion
LangGraph makes it easy to engineer flows with various cycles and decision points. Recent work has shown that this is powerful for code generation, where answers to coding questions can be constructed iteratively using using tests to check answers, reflect on failures, and iteratively improve the answer. We show that this can be implemented in LangGraph and test it on 20 questions related to LCEL for both code imports and execution. We find that context stuffing + LangGraph with reflection results in ~47% improvement in code execution relative context stuffing. The notebook is here and be extended to other codebases trivially.