
About Podium
Podium is a communication platform that helps small businesses connect quickly with customers via phone, text, email, and social media. Small businesses often have high-touch interactions with customers — think automotive dealers, jewelers, bike shops — yet are understaffed. Podium's mission is to help these businesses respond to customer inquiries promptly so that they can convert leads into sales.
Podium data shows that responding to customer inquiries within 5 minutes results in a 46% higher lead conversion rate than responding in an hour. To improve lead capture, Podium launched AI Employee, their agentic application (and flagship product) to engage local business customers, schedule appointments, and close sales.
Initially, Podium used the LangChain framework for single-turn interactions. As their agentic use cases grew more complex for a wide-ranging set of customers and domains, Podium needed better visibility into their LLM calls and interactions — and turned to LangSmith for LLM testing and observability.
Testing across the agentic development lifecycle
Establishing feedback loops was especially important to the agentic development lifecycle for Podium. LangSmith allowed the Podium engineers to test and continuously monitor their AI employee’s performance, adding new edge cases to their dataset to refine and test the model over time.
Podium’s testing approach looks like the following:
- Baseline Dataset Curation: Create an initial dataset to represent basic use cases and requirements for the agent. This serves as a foundation for testing and development.
- Baseline Offline Evaluation: Conduct initial tests using the curated dataset to assess the agent's performance against the basic requirements before shipping to production.
- Collecting Feedback:
- User-Provided Feedback: Collect direct input from users interacting with the agent.
- Online Evaluation: Use LLMs to self-evaluate and monitor the quality of responses using in real-time, flagging potential issues for further investigation.
- Optimization:
- Prompt Tuning: Refine the prompts used to guide the agent's responses.
- Retrieval Tuning: Adjust the retrieval mechanisms used to generate responses.
- Model Fine-Tuning: Use traced data to further train and specialize the model for specific tasks.
- Ongoing Evaluation:
- Offline Evaluation: Evaluate the agent's performance and identify opportunities for optimization using backtesting, pairwise comparisons, and other testing methods.
- Dataset Curation: Continuously update and expand the test dataset with new scenarios and edge cases for regression testing, ensuring new changes don't negatively impact existing capabilities.
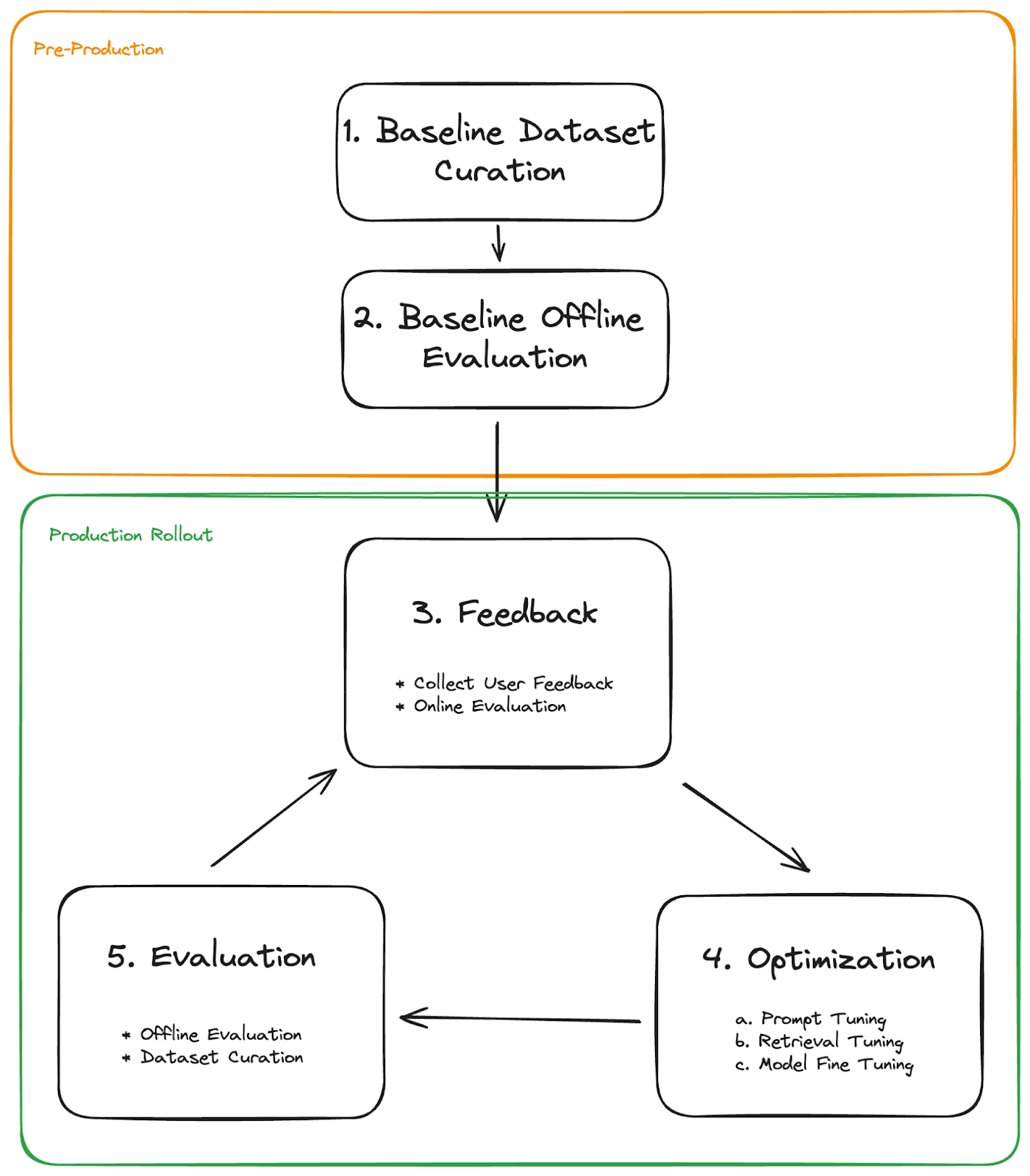
Dataset curation and fine-tuning agents with LangSmith
Prior to LangSmith, understanding a customer inquiry and what steps employees should take to resolve the inquiry was difficult, since the Podium engineers made 20-30 LLM calls per interaction. With LangSmith, they quickly got set up and logged and viewed traces to aggregate insights.
One specific challenge Podium ran into with their AI Employee was that the agent struggled to recognize when a conversation had naturally ended, resulting in awkward repeated goodbyes. To address this, Podium began by creating a dataset in LangSmith with various conversation scenarios, including ways different conversations might conclude.
Their engineering team then found it helpful to upgrade to a larger model, curating the outputs into a smaller model (using a technique called model distillation). Upgrading their model went smoothly since model inputs and outputs were automatically captured in LangSmith’s traces, allowing the team to easily curate datasets.
Podium engineers also enriched LangSmith traces with metadata on customer profiles, business types, and other parameters important to their business. They grouped traces using specific identifiers in LangSmith, making it easy to aggregate related traces during data curation. This enriched data enabled Podium to create a higher-quality and balanced dataset, which improved model fine-tuning and helped them avoid overfitting).
With this balanced dataset, the Podium team then compared the results from their fine-tuned model against results from their original, larger model using pairwise evaluations. This comparison allowed them to assess how well the upgraded model could improve the agent’s ability to know when to conclude a conversation.
After fine-tuning, Podium’s new model showed significant improvement in detecting where natural conversation should end for its agent. Podium’s F1 scores with the fine-tune model experienced a 7.5% improvement, going from 91.7% to 98.6% to exceed their quality threshold of 98%.
High-quality customer support for AI platform without engineering intervention
At Podium, engineers must understand when communications with customers go awry, so that they can keep shipping reliable and high-quality products.
Since publicly launching their AI Employee in January, it became critical for the Technical Product Specialists (TPS) at Podium to troubleshoot issues users were encountering in real-time. At Podium, the TPS team typically provides customer support for their small business customers. However, pinpointing the source of issues (and how to take action on them) was challenging.
Giving the TPS team access to LangSmith provided clarity, allowing the team to quickly identify customer-reported issues and determine: “Is this issue caused by a bug in the application, incomplete context, misaligned instructions, or an issue with the LLM?”
For Podium, identifying the type of customer issue guided them to the appropriate interventions:
- For bugs in the application: These are orchestration failures, such as an integration failing to return data. These require engineering intervention.
- For incomplete context: LLM is missing information needed to answer a question. These can be remediated by the TPS team by adding additional content.
- For misaligned instructions: Instructions are based on business requirements; any issues in the requirements can affect agent behavior. These can be remediated by the TPS team making changes in the content authoring system to better suit business requirements.
- For an LLM issue: Even with necessary context, an LLM may produce unexpected or incorrect information. These require engineering intervention.
For example, many car dealerships use Podium’s AI Employee to respond to customer inquiries. If the AI Employee mistakenly responds that a car dealership does not offer oil changes, the TPS team can use LangSmith’s playground feature to edit the system output and determine if a simple setting change in the Admin interface can resolve the issue.
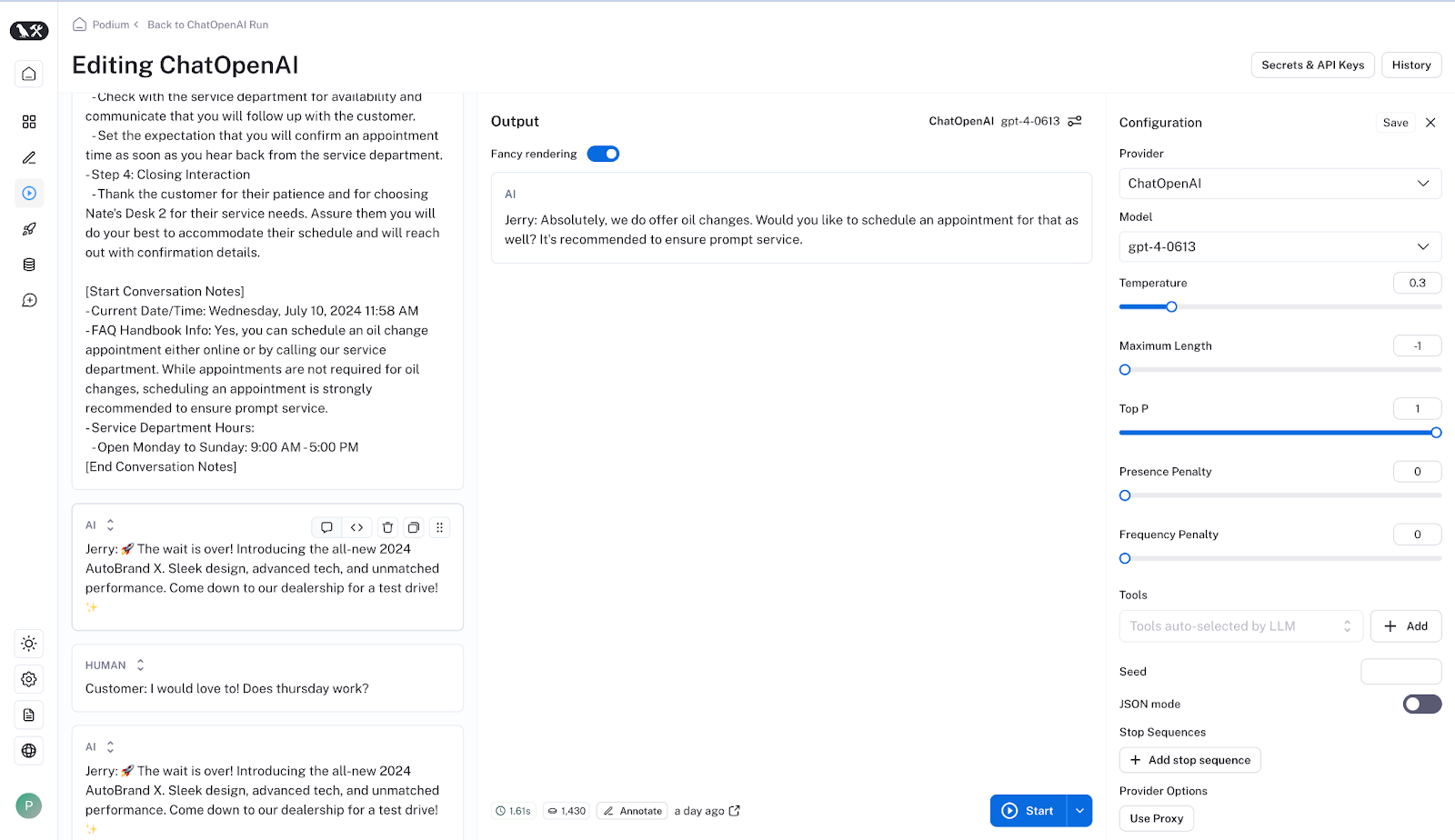
Before LangSmith, troubleshooting agent behavior often required engineering intervention. This was a time-consuming process that involved calling in engineers to first review model inputs and outputs, and then rewrite and refactor the code.
By giving their TPS team access to LangSmith traces, Podium has reduced the need for engineering intervention by 90%, allowing their engineers to focus more on development instead of support tasks.
In summary, using LangSmith led to:
- Increased efficiency of Podium’s support team by enabling them to resolve issues more quickly and independently.
- Improved customer satisfaction (CSAT) scores for both support interactions and Podium’s AI-powered services.
What’s Next for Podium
By integrating LangSmith and LangChain, Podium has gained a competitive edge in the space of customer experience tools. LangSmith has enhanced observability and simplified the management of large datasets and optimizing model performance. The Podium team has also been integrating LangGraph into its workflow, reducing complexity in their agent orchestration while serving different target customers, while increasing controllability over their agent conversations.
Together, these suite of products have allowed Podium to focus on their core value proposition — help small businesses capture leads more effectively — and efficiently design, test, and monitor their LLM applications.
Podium is hiring across roles to help local businesses win. Inspired by Podium’s story? You can also try out LangSmith for free or talk to a LangSmith expert to learn more.
And for a more comprehensive best practices for testing and evaluating your LLM application, check out this guidebook.