
At Sequoia’s AI Ascent conference in March, I talked about three limitations for agents: planning, UX, and memory. Check out that talk here. In this post, I will dive more into planning for agents.
If you ask any developer building agents with LLMs, he or she will probably cite the inability for agents to plan and reason well as a big pain point for agent reliability. What does planning mean for an agent, and how do we see people currently overcoming this shortcoming? What is (our best guess at what) the future of planning and reasoning for agents will look like? We’ll cover all of this below.
What exactly is meant by planning and reasoning?
Planning and reasoning by an agent involves the LLM’s ability to think about what actions to take. This involves both short-term and long term steps. The LLM evaluates all available information and then decides: what are the series of steps that I need to take, and which is the first one I should take right now?
Most of the time, developers use function calling (also known as tool calling) to let LLMs choose what actions to take. Function calling is a capability first added to LLM APIs by OpenAI in June of 2023 and then by others in late 2023/early 2024. With function calling, you can provide JSON schemas for different functions and have the LLM output object match one (or more) of those schemas. For more information on how to do this, see our guide here.
Function calling is used to let the agent choose what to do as an immediate action. Often times though, to successfully accomplish a complex task you need to take a number of actions in sequence. This long-term planning and reasoning is a tougher task for LLMs for a few reasons. First, the LLM must think about a longer time-horizon goal, but then jump back into a short-term action to take. Second, as the agent takes more and more actions, the results of those actions are fed back to the LLM; this lead to the context window growing, which can cause the LLM to get “distracted” and perform poorly.
Like most things in the LLM world, it is tough to measure exactly how well current models do at planning and reasoning. There are reasonable benchmarks like the Berkeley Function Calling Leaderboard for evaluating function calling. We’ve done a little research on evaluating multi-step applications. But the best way to get a sense for this is build up an evaluation set for your specific problem and attempt to evaluate on that yourself.
What are current fixes to improve planning by agents?
The lowest hanging fix for improving planning is to ensuring the LLM has all the information required to reason/plan appropriately. As basic as this sounds, oftentimes the prompt being passed into the LLM simply does not contain enough information for the LLM to make a reasonable decision. Adding a retrieval step, or clarifying the prompt instructions, can be an easy improvement. That’s why its crucial to actually look at the data and see what the LLM is actually seeing.
After that, I’d recommend you try changing the cognitive architecture of your application. By “cognitive architecture”, I mean the data engineering logic your application uses to reason. There are two categories of cognitive architectures you can look towards to improve reasoning: general purpose cognitive architectures and domain specific cognitive architectures.
General purpose cognitive architectures vs domain specific cognitive architectures
General purpose cognitive architectures attempt to achieve better reasoning generically. They can be applied to any task. One good example of this is the “plan and solve” architecture. This paper explores an architecture where first you come up with a plan, and then execute on each step in that plan. Another general purpose architecture is the Reflexion architecture. This paper explores putting an explicit “reflection” step after the agent does a task to reflect on whether it did it correctly or not.
Though these ideas show improvement, they are often too general for practical use by agents in production. Rather, we see agents being built with domain-specific cognitive architectures. This often manifests in domain-specific classification/routing steps, domain specific verification steps. Some of the general ideas of planning and reflection can be applied here, but they are often applied in a domain specific way.
As a concrete example, let’s look at the AlphaCodium paper. This achieved state-of-the-art performance by using what they called “flow engineering” (another way to talk about cognitive architectures). See a diagram of the flow they use below.
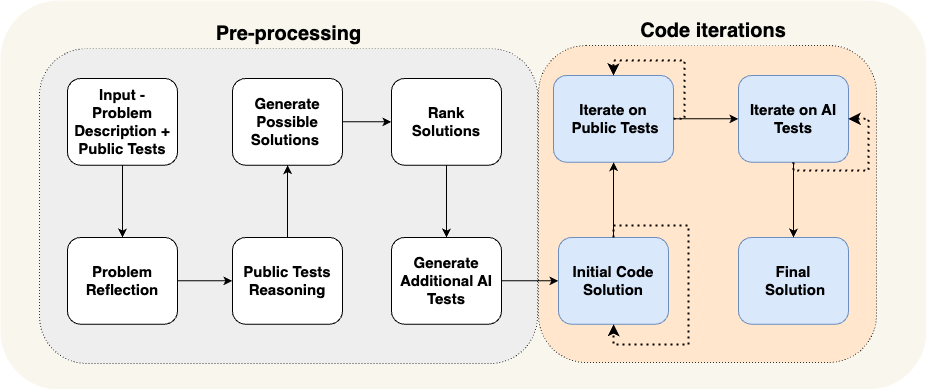
The flow is VERY specific to the problem they are trying to solve. They are telling the agent what to do in steps - come up with tests, then come up with a solution, then iterate on more tests, etc. This cognitive architecture is highly domain specific - it wouldn’t help you write essays, for example.
Why are domain specific cognitive architectures so helpful?
There are two ways I like to think about this.
First: you can view this as just another method of communicating to the agent what it should do. You can communicate instructions in prompt instructions, or you can hardcode specific transitions in code. Either one is valid! Code is fantastic way of communicating what you want to have happen.
Second: this is essentially removing the planning responsibilities from the LLM to us as engineers. We are are basically saying: “don’t worry about planning, LLM, I’ll do it for you!” Of course, we’re not removing ALL planning from the LLM, as we still ask it do some planning in some instances.
For example, let’s look back at the AlphaCodium example above. The steps in the flow are basically us doing planning for the LLM! We’re telling it to first write tests, then code, then run the tests, etc. This is presumably what the authors thought a good plan for writing software was. If they were planning how to do a problem, this is how they would do it. And rather than tell the LLM to do in the prompt - where it may ignore it, not understand it, not have all the details - they told the system to do it by constructing a domain specific cognitive architecture.
We’re making building these custom cognitive architectures easier with LangGraph. One of the big focus points of LangGraph is on controllability. We’ve designed LangGraph to very low level and highly controllable - this is because we’ve seen that level of controllability is 100% needed to create a reliable custom cognitive architecture.
What does the future of planning and reasoning look like?
The LLM space has been changing and evolving rapidly, and we should keep that in mind when building applications, and especially when building tools.
My current take is that general purpose reasoning will get more and more absorbed into the model layer. The models will get more and more intelligent, whether through scale or research breakthroughs - it seems foolish to bet against that. Models will get faster and cheaper as well, so it will become more and more feasible to pass a large amount of context to them.
However, I believe that no matter how powerful the model becomes, you will always need to communicate to the agent, in some form, what it should do. As a result, I believe prompting and custom architectures are here to stay. For simple tasks, prompting may suffice. For more complex tasks, you may want to put the logic of how it should behave in code. Code-first approaches may be faster, more reliable, more debuggable, and oftentimes easier/more logical to express.
I went on a podcast recently with Sonya and Pat from Sequoia and talked about this topic. They drew a fantastic diagram showing how the role / importance of prompting, cognitive architectures, and the model may evolve over time.
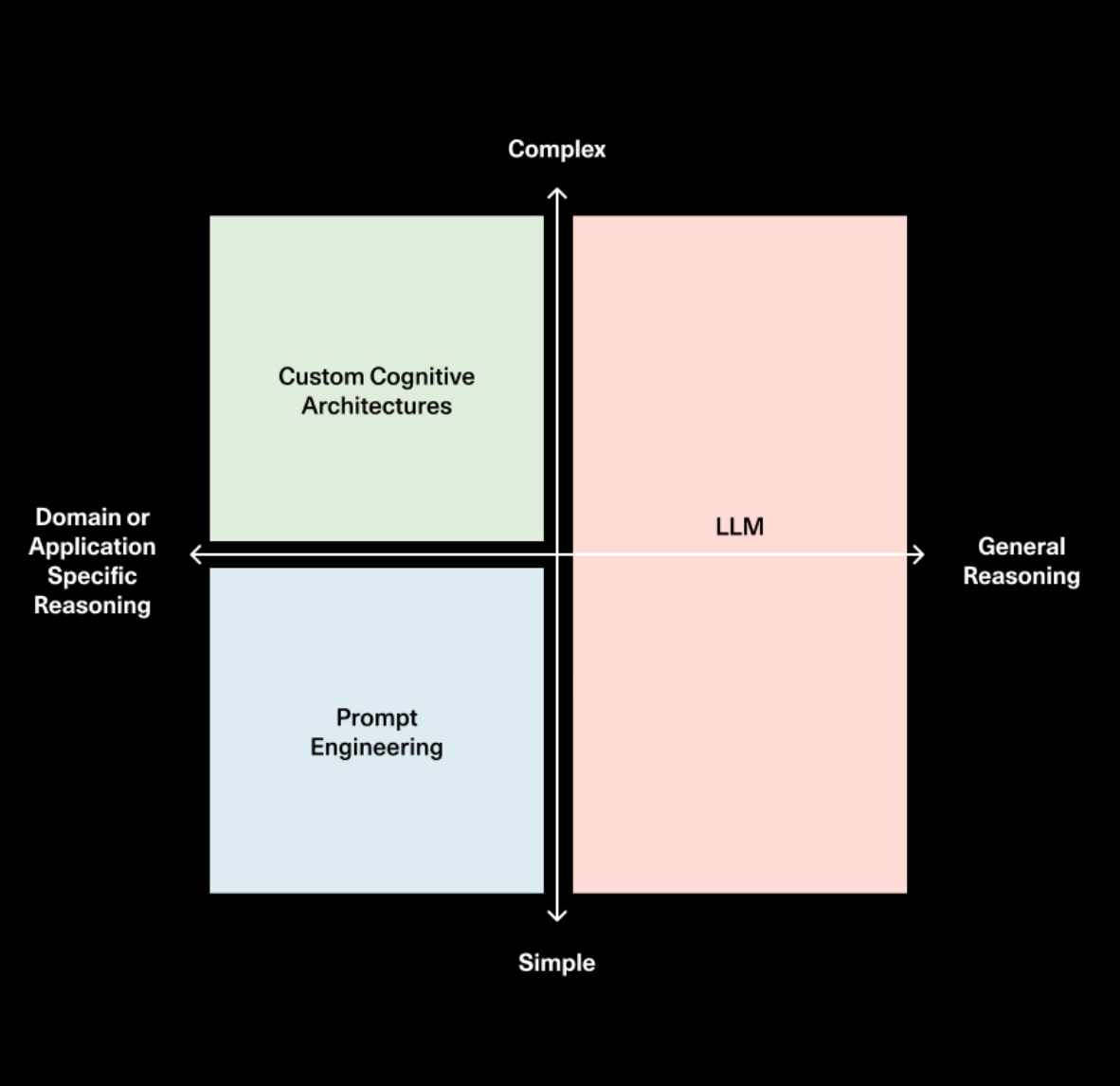
So while the planning and reasoning of LLMs will certainly get better, we also strongly believe that if you are building a task-specific agent then you will need to build a custom cognitive architecture. That’s why we’re so bullish on the future of LangGraph.