Promptim is an experimental prompt optimization library to help you systematically improve your AI systems.
Promptim automates the process of improving prompts on specific tasks. You provide initial prompt, a dataset, and custom evaluators (and optional human feedback), and promptim runs an optimization loop to produce a refined prompt that aims to outperform the original.
From evaluation-driven development to prompt optimization
A core responsibility of AI engineers is prompt engineering. This involves manually tweaking the prompt to produce better results.
A useful way to approach this is through evaluation-driven development. This involves first creating a dataset of inputs (and optionally, expected outputs) and then defining a number of evaluation metrics. Every time you make a change to the prompt, you can run it over the dataset and then score the outputs. In this way, you can measure the performance of your prompt and make sure its improving, or at the very least not regressing. Tools like LangSmith help with dataset curation and evaluation.
The idea behind prompt optimization is to use these well-defined datasets and evaluation metrics to automatically improve the prompt. You can suggest changes to the prompt in an automated way, and then score the new prompt with this evaluation method. Tools like DSPy have been pioneering efforts like this for a while.
Why do prompt optimization?
There are several motivations for prompt optimization:
Save time: Manual prompt engineering can often be a time-intensive process. Automated prompt optimization can speed up prompt engineering efforts and save engineering time.
Bring rigor: Prompt engineering is sometimes more of an art than a science – so this brings some rigor to the process. Note that evaluation-driven development in general can help accomplish this.
Facilitate swapping between models: Different models often require different prompting strategies. Switching model providers isn't as simple as changing the URL you are calling; you also often need to change the prompt. Prompt optimization can speed up that process, as you focus most of your effort on developing evals (which are model agnostic) as opposed to prompting (which is not model agnostic).
How Promptim works
We're excited to release our first attempt at prompt optimization. It is an open source library (promptim) that integrates with LangSmith (which we use for dataset management, prompt management, tracking results, and (optionally) human labeling.
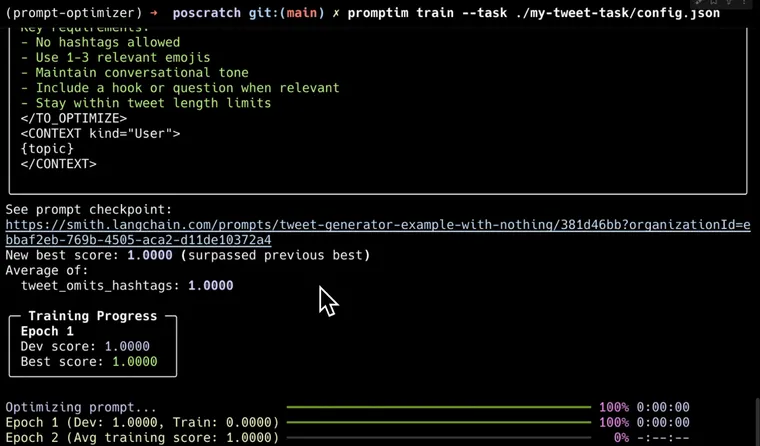
The core algorithm is as follows:
- Specify a LangSmith dataset, a prompt in LangSmith, and evaluators defined locally. Optionally, you can specify
train/dev/testdataset splits. - We run the initial prompt over the
dev(or full) dataset to get a baseline score. - We then loop over all examples in the
train(or full) dataset. We run the prompt over all examples, then score them. We then pass the results (inputs, outputs, expected outputs, scores) to a metaprompt and ask it to suggest changes to the current prompt - We then use the new updated prompt to compute metrics again on the
devsplit. - If the metrics show improvement, the the updated prompt is retained. If no improvement, then the original prompt is kept.
- This is repeated
Ntimes
Optionally, you can add a step where you leave human feedback. This is useful when you don't have good automated metrics, or want to optimize the prompt based on feedback beyond what the automated metrics can provide. This uses LangSmith's Annotation Queues.
Limitations of prompt optimization
Although we are excited by prompt optimization, we don't think this is a silver bullet. It's still worthwhile to have a human-in-the-loop in this process - even if it's just to provide a sanity check for the final result. That's part of the reason why we use LangSmith's Prompt Hub to store prompts — so you can easily review the prompts afterwards.
Comparing Promptim to DSPy
DSPy is the leading tool in the optimization space. It's worth comparing our approach to theirs.
First, this initial effort is focused on just optimizing a single prompt. DSPy focuses on optimizing your whole "compound AI system". We chose to focus on a single prompt for now as we think it is a more tractable problem at the moment.
Second, we focus more on still having the human in-the-loop, while DSPy removes the human a bit more. One example of this through hooking this up to annotation queues for human feedback as part of the optimization process. Another example is storing these prompts in LangSmith for easy review after the fact. A final example is tracking evaluation results in LangSmith.
Third, we focus solely on rewriting the prompt and aim to be really good at that, while DSPy offers a wider breadth of solutions to optimize your system (finetuning, few shot prompting).
promptim and dspy as different tools for different problems.Future work
As the foundation models stabilize, we are getting more and more excited about prompt optimization. Things we are looking forward to:
- Pushing more on dynamic few shot prompting
- Integrating
promptiminto the LangSmith UI - Adding more optimization methods to
promptim - Optimizing LangGraph graphs as a whole, not just prompts (ideally through an integration with DSPy)
You can try out Promptim today: pip install promptim. Check out this YouTube video for a walkthrough, and drop us a line on GitHub or Twitter with any feedback.