The single biggest pain point we hear from developers taking their apps into production is around testing and evaluation. This difficulty is felt more acutely due to the constant onslaught of new models, new retrieval techniques, new agent types, and new cognitive architectures.
Over the past months, we've made LangSmith the best place to go for LLM architecture evaluation (test comparison view, dataset curation). Today we're making it possible to share evaluation datasets and results, to more easily enable community-driven evaluation and benchmarks. We're also excited to share the new langchain-benchmarks package so you can reproduce these results and easily experiment with your architecture.
Test sharing makes it easy for anyone on LangSmith to publish all the data and metrics on how different architectures perform on the same set of tasks. As an added benefit, we're not just logging the end results - each evaluation result includes the full accompanying traces for the tested chains. This means you can go beyond aggregate statistics and system-level outputs and see the step-by-step execution of different systems on the same data point.
Background
Over the past year, the tooling and model quality for building with LLMs has continued to improve with breakneck speed. Each week, dozens of new prompting and compositional techniques are proposed by developers and researchers, all claiming superior performance characteristics. The LangChain community has implemented many of these, from simple prompting techniques like chain of density and step-back prompting, to advanced RAG techniques all the way to RL chains, generative agents, and autonomous agents like BabyAGI. For structured generation alone, we have (thankfully) evolved from emotion prompting techniques to fine-tuned APIs like function calling and grammar-based sampling.
With the launch of Hub and LangChain Templates, the release rate of new architectures continues to accelerate. But which of these approaches will translate to performance gains in YOUR application? What tradeoffs are assumed by each technique?
It can be hard to separate the signal from the noise, and the abundance of options makes reliable and relevant benchmarks that much more important. When it comes to grading language models on general tasks, public benchmarks like HELM or EleutherAI’s Test Harness are great options. For measuring LLM inference speed and throughput, AnyScale’s LLMPerf benchmarks can be a guiding light. These tools are excellent for comparing the underlying capability of language models, but they don't necessarily reflect their real-world behavior within your application.
LangChain’s mission is to make it as easy as possible to build with LLMs, and that means helping you stay up to date on the relevant advancements in the field. LangSmith’s evaluation and tracing experience helps you easily compare approaches in aggregate and on a sample level, and it makes it easy to drill down into each step to identify the root cause for changes in behavior.
With public datasets and evals, you can see the performance characteristics of any reference architecture on a relevant dataset so you can easily separate the signal from the noise.
📑 LangChain Docs Q&A Dataset
The first benchmark task we are including is a Q&A dataset over LangChain's documentation. This is a set of hand-crafted question-answer pairs we wrote over LangChain’s python docs. The questions are written to test RAG systems' ability to answer correctly, even if an answer requires information from multiple documents or when the question conflicts with the document's knowledge.
As a part of the initial release, we have evaluated various implementations that differ across a few dimensions:
- The language model used (OpenAI, Anthropic, OSS models)
- The "cognitive architecture" used (conversational retrieval chain, agents)
You can check out the link above to review the results or continue with the information below!
🦜💪 LangChain Benchmarks
To help you experiment with your own architectures on the Q&A dataset, we are publishing a new langchain-benchmarks package (docs link). This package facilitates experimentation and benchmarking for key functionality when building with LLMs. In addition to the are publishing benchmarks extraction, agent tool use, and retrieval-based question answering.
For each dataset, we provide functionality to easily test different LLMs, prompts, indexing techniques, and other tooling so you can quickly weigh the tradeoffs in different design decisions and pick the best solution for your application.
In this post, we'll review some results from one of the question-answering tasks to show how it works!
Comparing Simple RAG Approaches
In our initial benchmarks, we evaluated LLM architectures based on the following templates:
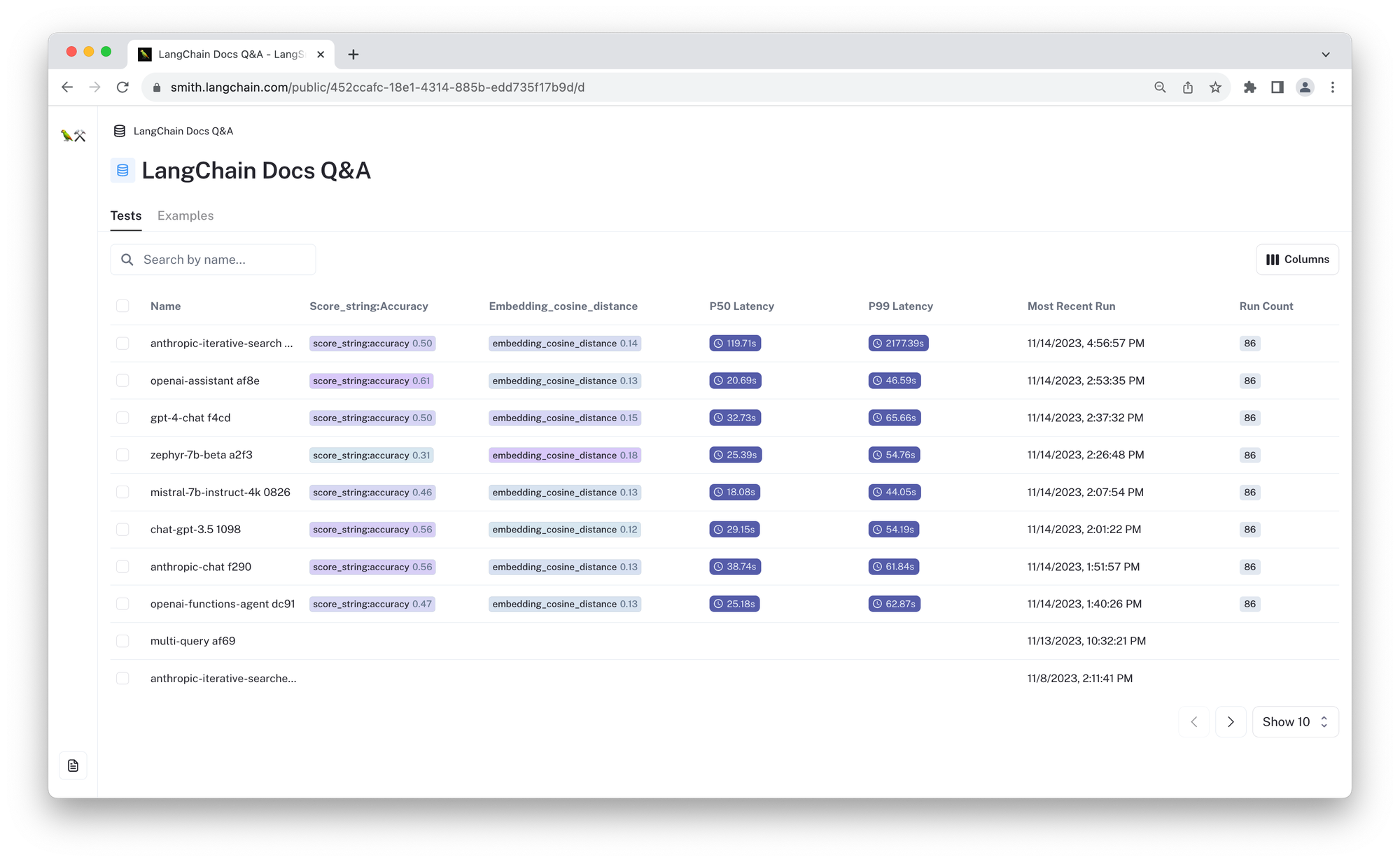
| Cognitive Architecture | Test | Score ⬆️ | Cosine Dist ⬇️ | 🔗 |
|---|---|---|---|---|
| Conversational Retrieval Chain | zephyr-7b-beta a2f3 | 0.31 | 0.18 | link |
| mistral-7b-instruct-4k 0826 | 0.46 | 0.13 | link | |
| gpt-4-chat f4cd | 0.50 | 0.15 | link | |
| chat-gpt-3.5 1098 | 0.56 | 0.12 | link | |
| anthropic-chat f290 | 0.56 | 0.13 | link | |
| Agent | openai-functions-agent dc91 | 0.47 | 0.13 | link |
| gpt-4-preview-openai-functions-agent 5832 | 0.58 | 0.142 | link | |
| anthropic-iterative-search 1fdf | 0.50 | 0.14 | link | |
| Assistant | openai-assistant af8e | 0.62 | 0.13 | link |
The links above let you view the results for each configuration and compare each using the automatic metrics. For these tests, we measure the cosine distance between the predicted and reference responses as well as an accuracy "score" using LangChain’s LLM-based scoring evaluator. For the accuracy score, a larger number is better (⬆️) and for the cosine distance, a lower number is better (⬇️). Below, we describe the tests in more detail. See the prompt used for the evaluator here.
Conversational retrieval chains
The following experiments use different models within a simple retrieval chain implementation. The input query is directly embedded using OpenAI's text-embedding-ada-002, and the four most relevant docs are retrieved from a ChromaDB vectorstore based on semantic similarity. We compare the following LLMs below:
mistral-7b-instruct-4k 0826: applies open-source Mistral 7B model (with a 4k context-window) to respond using retrieved docs. This model was adapted using instruction tuning.zephyr-7b-beta a2f3: applies the open-source Zephyr 7B Beta model, which is instruction-tuned version of Mistral 7B, to respond using retrieved docs.chat-3.5-3.5 1098: usesgpt-3.5-turbo-16kfrom OpenAI to respond using retrieved docs.gpt-4-chat f4cd: usesgpt-4by OpenAI to respond based on retrieved docs.anthropic-chat f290: usesclaude-2by Anthropic to respond based on retrieved docs.
Agents
The following tests apply agent architectures to answer the questions. The agents are given a single retriever tool, which wraps the same vector store retriever described above. Agents are able to respond directly or call the retriever any number of times with their own queries to answer a question. In practice, we find that the agents typically call the tool once and then respond.
openai-functions-agent dc91: uses the function calling API from OpenAI (now called the 'tool calling' API) to interact with the documentation retriever. In this case, the agent is driven by thegpt-3.5-turbo-16kmodel.gpt-4-preview-openai-functions-agent 5832: same as above but uses the newgpt-4-1106-previewmodel, which is a larger, more capable model than gpt-3.5.anthropic-iterative-searche 1fdf: applies the iterative search agent, which prompts Anthropic'sclaude-2model to call the retrieval tool and uses XML formatting to improve reliability of the structured text generation.
Assistant API
Finally, we tested OpenAI's new assistants API in openai-assistant af83. This still uses our same retrieval tool, but it uses OpenAI's execution logic to decide the query and final response. This agent ended up earning the highest performance of all our tests.
Reviewing the Results
The comparison views also make it easy to manually review the outputs to get a better sense for how the models behave, so you can make adjustments to your cognitive architecture and update the evaluation techniques to address any failure modes you identify.
To illustrate, let's compare the conversational retrieval chain powered by Mistral-7b RAG application to similarly architected application powered by GPT-3.5: (comparison link). Using the tested prompts, GPT-3.5's performance handily outperforms the Mistral 7B model in terms of the aggregate metrics generated for this example (0.01 difference in average cosine difference but lags the average "accuracy" score by 0.1).
Note: None of the open-source models tested in these experiments matched the aggregate performance of the proprietary APIs off-the-shelf, though additional prompt engineering may close the gap.
This is interesting, but in order to decide how to improve, you'll need to look at the data. LangSmith makes this easy. Take the following challenging example:

For this data point, neither model was able to answer correctly; the question itself requires knowledge of absence, which is a challenging task for RAG applications that often leads to hallucinations.
When inspecting this by eye, the gpt-3.5-turbo model clearly hallucinates, even providing a nice made-up link (https://docs.langchain.com/java-sdk). The mistral models' response is preferable, since it doesn't generate inaccuracies (no official LangChain java SDK exists).
To diagnose why the models responded the way they did, you can click through to view the full trace of that architecture.

It's clear from the trace (link) that the retrieved documents are all quite irrelevant to the original query. If you are using a model like gpt-3.5 and getting hallucinations like this, you can try adding an additional system prompt reminding the model to only respond based on the retrieved content, and you can work to improve the retriever to filter out irrelevant documents.
Let's review another data point, this one where gpt-3.5 responded correctly but mistral did not. If you compare the outputs, you can see that mistral was influenced too much by the document content and mentioned the class from the docs rather than the direct answer.
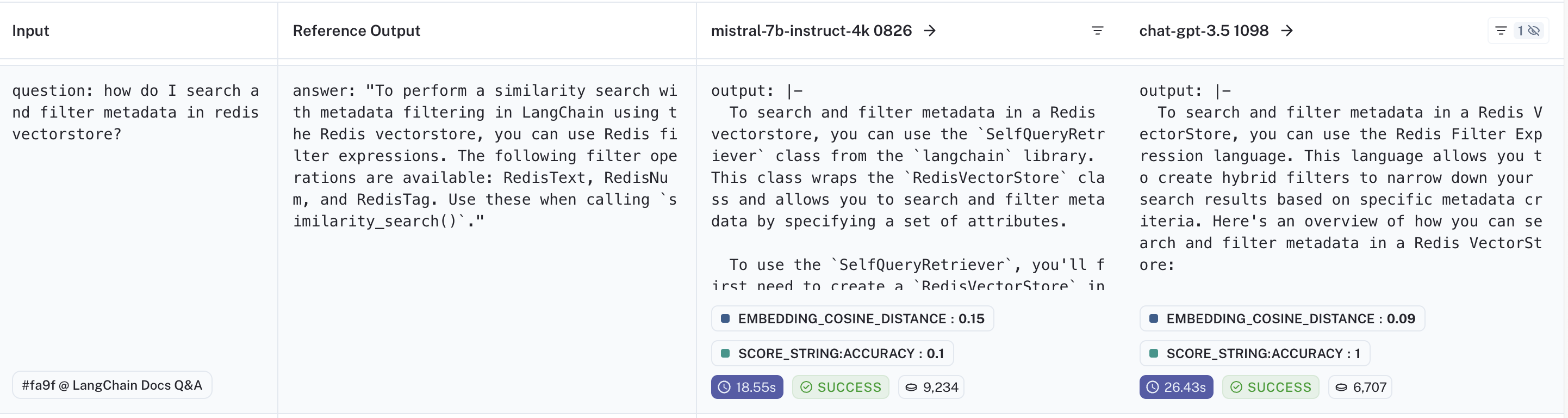
If you look at the trace, you can see that "SelfQueryRetriever" is only mentioned in Document 5 of the retrieved docs, meaning it's the least relevant document. That the LLM hinges its response based on this document signals that perhaps we could improve its performance by re-ordering the input.
To check this hypothesis, you can open the LLM run in the playground. By swapping documents 1 and 5, we can see that the LLM responds with the correct answer. Based on this check, we could update the order we present the documents and re-run evaluation!

Apart from response accuracy, latency is another important metric when building an LLM application. In our case, mistral-7b's median response time was 18 seconds, 11 seconds faster than gpt-3.5's.

Measuring quality metrics alongside "system metrics" can help you pick the "right-sized" model and architecture for the job.
Finally, let's compare the openai-assistant af83 with the similar gpt-4-preview-openai-functions-agent 5832 test. They use the same underlying model and retriever tool and work as an agent, but the former test uses OpenAI's assistant API. You can view the comparison here: link.
An example data point where the assistant out-performs the agent is this (example). Both say that they cannot see an explicit answer to the question (since the retriever is the same), but the assistant is willing to provide context on how strict is used in other contexts as a pointer for the user.

More to come
Over the coming weeks, we plan to add benchmarks for each of LangChain’s most popular use cases to make it easier. Check in on the LangChain benchmarks repository for updates and open a feature request to ensure that your use cases are covered.
You can also download the langchain-benchmarks package to try out your RAG application on this and other tasks.