Key Links
There's great interest in seamlessly connecting natural language with diverse types of data (structured, unstructured, and semi-structured). But, this emerging "LUI" (language user interface) has specific challenges/considerations for each data type:
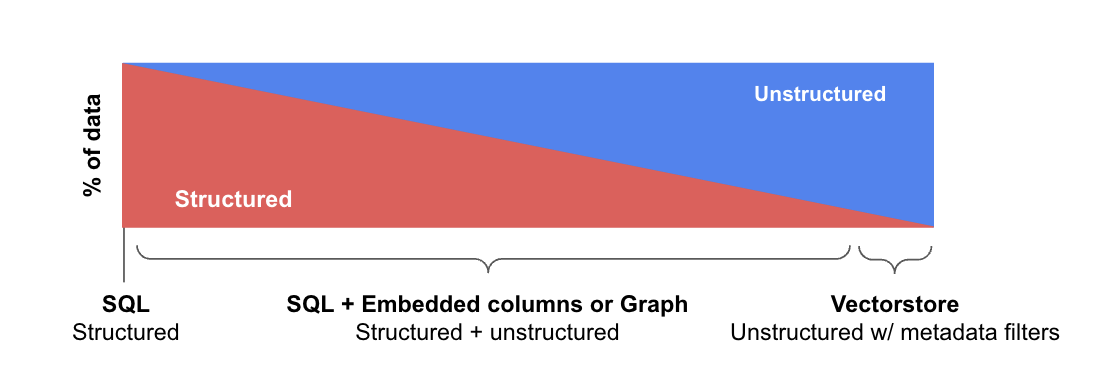
- Structured Data: Predominantly housed within SQL or Graph databases, structured data is characterized by predefined schemas and organized in tables or relations, making it amenable to precise query operations.
- Semi-structured Data: Semi-structured data blends structured elements (e.g., tables in a document or relational database) with unstructured elements (e.g., text or an embedding column in a relational database).
- Unstructured Data: Typically stored in vector databases, unstructured data consists of information without a predefined model, frequently accompanied by structured metadata that enables filtering.
To address these challenges, LLMs have great capacity for query construction, the process of converting natural language into a specific query syntax for each data type. For this third installment in our blog series on advanced retrieval, we'll be covering various strategies for query construction (see our blog posts on Multi-Representation Indexing and Query Transformation for more.)
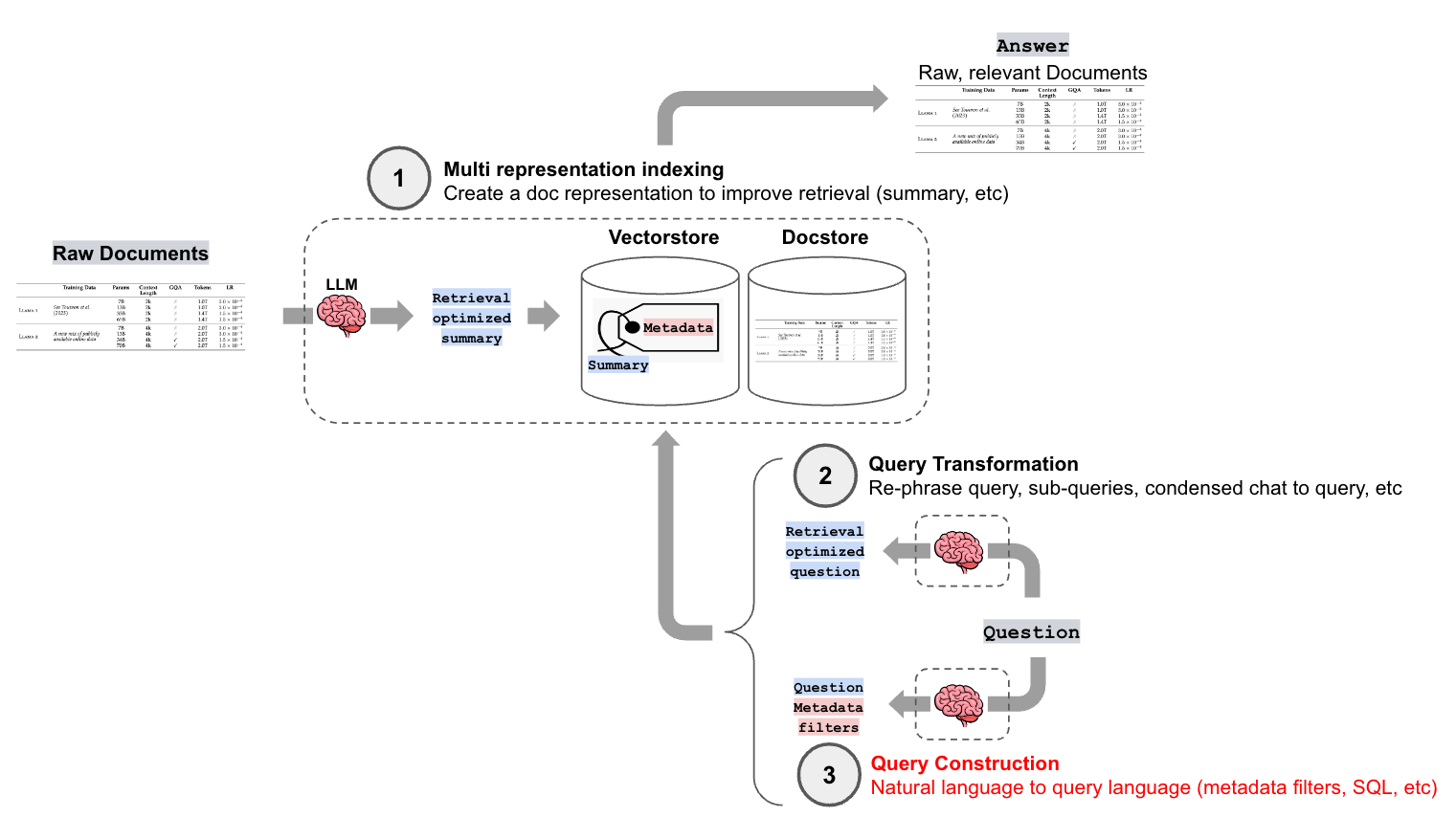
What is Query Construction?
With typical retrieval augmented generation (RAG), a user query is converted into a vector representation. This vector is then compared to vector representations of the source documents to find the most similar ones. This works fairly well for unstructured data (see our blog posts on Multi-Representation Indexing and Query Transformation), but what about structured data?
Most data in the world has some structure. Much of this data lives in relational (e.g., SQL) or graph databases. And even unstructured data often associated structured metadata (e.g., things like the author, genre, data published, etc).
For example, consider the query what are movies about aliens in the year 1980. There is a portion (aliens) that we may want to look up semantically, but also a component ("year == 1980") that we want to look up in an exact way.
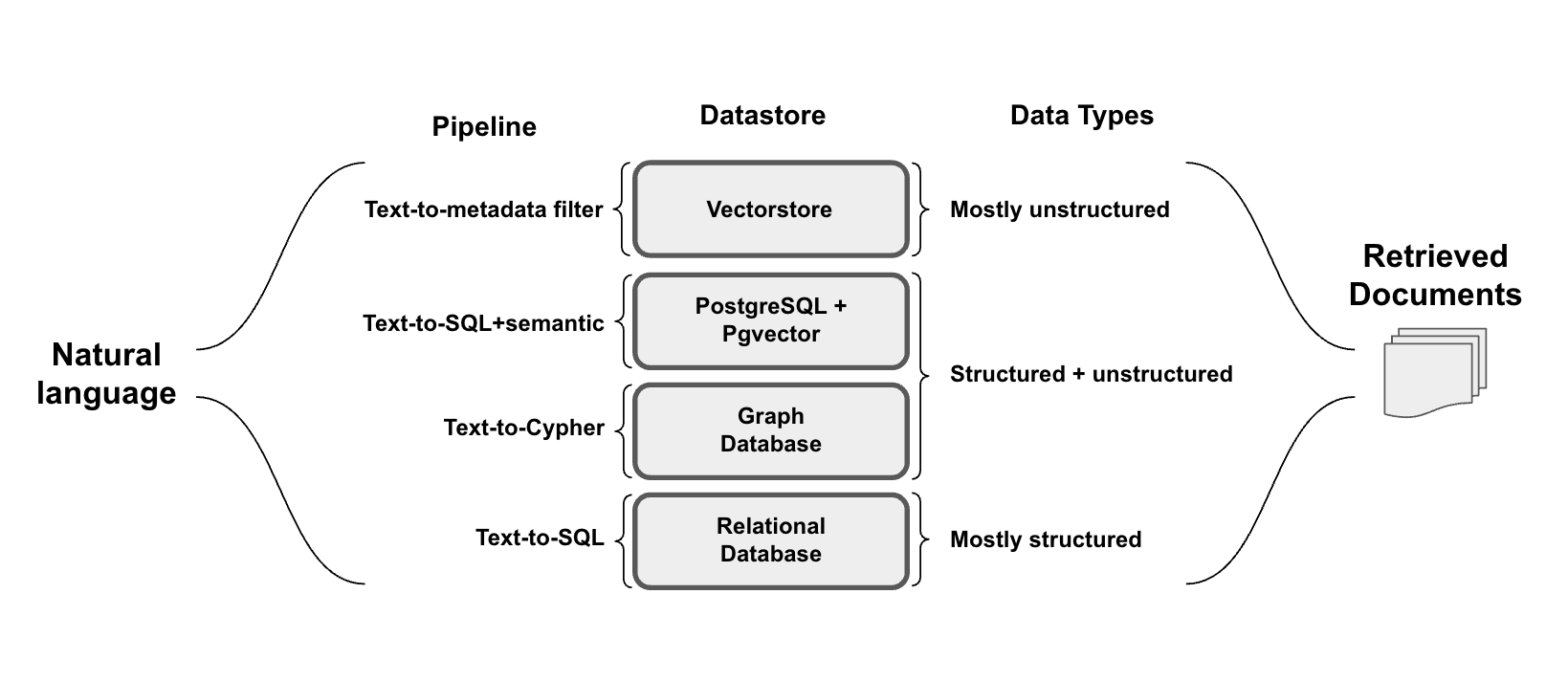
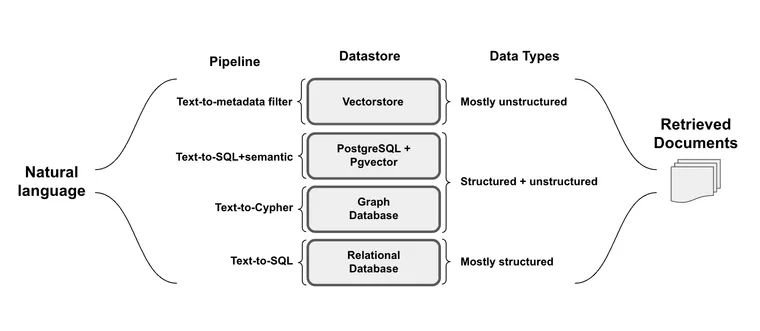
Below we will highlight several examples of query construction and provide relevant cookbooks, templates, and documentation for each one:
Text-to-metadata-filter
Vectorstores equipped with metadata filtering enable structured queries to filter embedded unstructured documents. The self-query retriever can translate natural language queries into these structured queries using a few steps:
- Data Source Definition: At its core, the self-query retriever is anchored by a clear specification of the relevant metadata files (e.g., in the context of song retrieval, this might be artist, length, and genre).
- User Query Interpretation: Given a natural language question, the self-query retriever will isolate the query (for semantic retrieval) and the filter for metadata filtering. For instance, a query for
songs by Taylor Swift or Katy Perry about teenage romance under 3 minutes long in the dance pop genreis decomposed into a filter and query. - Logical Condition Extraction: The filter itself is crafted from vectorstore defined comparators and operators like
eqfor equals orltfor less than. - Structured Request Formation: Finally, the self-query retriever assembles the structured request, bifurcating the semantic search term (query) from the logical conditions (filter) that streamline the document retrieval process.
We can define a chain to execute the above steps, which accepts a user question and returns a StructuredQuery object that encapsulates the necessary filters:
# Generate a prompt and parse output
prompt = get_query_constructor_prompt(document_content_description, metadata_field_info)
output_parser = StructuredQueryOutputParser.from_components()
query_constructor = prompt | llm | output_parser
# Invoke the query constructor with a sample query
query_constructor.invoke({
"query": "Songs by Taylor Swift or Katy Perry about teenage romance under 3 minutes long in the dance pop genre"
})
The structured request would look like:
{
"query": "teenager love",
"filter": "and(or(eq(\"artist\", \"Taylor Swift\"), eq(\"artist\", \"Katy Perry\")), lt(\"length\", 180), eq(\"genre\", \"pop\"))"
}
This approach can significantly improve RAG answer quality when interacting with vector databases because logical filter conditions inferred directly from the user question gate the text chunks passed to the LLM for final answer synthesis.
Read more:
- Docs: Self-querying retriever
- Template: Self-query Supabase vector db
- Template: Self-query Elastic vector db
Text-to-SQL
On the other end of the data continuum, SQL / relational databases are important sources of largely structured data. Considerable effort has focused on translating natural language into SQL requests, with a few notable challenges such as:
- Hallucination: LLMs are prone to ‘hallucination’ of fictitious tables or fields, thus creating invalid queries. Approaches must ground these LLMs in reality, ensuring they produce valid SQL aligned with the actual database schema.
- User errors: Text-to-SQL approaches should be robust to user mis-spellings or other irregularities in the user input that could results in invalid queries.
With these challenges in mind a few tricks have emerged:
- Database Description: To ground SQL queries, an LLM must be provided with an accurate description of the database. One common text-to-SQL prompt employs an idea reported in several papers: provide the LLM with a
CREATE TABLEdescription for each table, which include column names, their types, etc followed by three example rows in a SELECT statement. - Few-shot examples: Feeding the prompt with few-shot examples of question-query matches can improve the query generation accuracy. This can be achieved by simply appending standard static examples in the prompt to guide the agent on how it should build queries based on questions.
- Error Handling: When faced with errors, data analysts don't give up—they iterate. We can use tools like SQL agents (here) to recover from errors.

- Finding misspellings in proper nouns: When querying for proper nouns like names, a user may inadvertently write it incorrectly (e.g.
Franc Sinatra). We can allow an agent to search for proper nouns against a vectorstore, which houses correct spellings for relevant proper nouns in the SQL database.
Read more:
- Docs: QA over structured data
- Blog: LLMs and SQL
- Blog: Incorporating domain specific knowledge in SQL-LLM solutions
Text-To-SQL+semantic
In the middle of the data continuum, mixed type (structured and unstructured) data storage is increasingly common. The addition of vector support to relational databases is a key enabler of approaches that support hybrid retrieval (see recent video from AI Engineer summit here). In particular, the open-source pgvector extension for PostgreSQL marries the expressiveness of SQL with the nuanced understanding of semantics provided by semantic search. Pgvector has reported favorable performance and cost relative to vectorstores like Pinecone.
Pgvector makes it possible to execute similarity search (e.g., cosine, L2 distance, inner product) over a embeddings vector column the <-> operator:
SELECT * FROM tracks ORDER BY "name_embedding" <-> {sadness_embedding}
From the above query, we can use LIMIT 3 to get the top 3 saddest tracks (similar to top_k value from standard kNN), but also more complex operations, such as picking the saddest one, and the 90th and 50th percentile for some reason. This unlocks two important new capabilities:
- We can perform semantic searches that are infeasible with a vectorstore
- We can enhance text-to-SQL with knowledge of the semantic operator. For example, it unlocks text-to-semantic searches (e.g., finding songs with titles conveying specific feelings) and SQL queries (e.g., filtering by genre).
Following the album-song examples, with this approach we could find albums containing the most songs matching a certain sentiment (using semantic similarity as a filter or count for tabular data) or find sad songs from albums with "lovely" titles (combining two semantic searches in one single query, which wouldn’t be possible using a vector database with metadata filtering).
Read more:
Text-to-Cypher
While vector stores readily handle unstructured data, they don't understand the relationships between vectors. And while SQL databases can model relationships, schema changes can be disruptive and costly. Knowledge graphs can address these challenges by modeling the relationships between data and extending the types of relationships without a major overhaul. They are desirable for data that has many-to-many relationships or hierarchies that are difficult to represent in tabular form.
Like relational databases often use SQL, graph databases often use a specific query language called Cypher, which is designed to provide a visual way of matching patterns and relationships. It relies on the following ascii-art type of syntax:
(:Person {name:"Tomaz"})-[:LIVES_IN]->(:Country {name:"Slovenia"})
This pattern describes a node with a label Person and the name property Tomaz that has a LIVES_IN relationship to the Country node of Slovenia. Like the above examples, text-to-Cypher can translate natural language to Cypher queries:
from langchain.chains import GraphCypherQAChain
graph.refresh_schema()
cypher_chain = GraphCypherQAChain.from_llm(
cypher_llm = ChatOpenAI(temperature=0, model_name='gpt-4'),
qa_llm = ChatOpenAI(temperature=0), graph=graph, verbose=True,
)
Because generating valid Cypher can be a complex task, it is recommended to use performant LLMs like GPT-4 to generate Cypher statements as the cypher_llm. As shown above, we can then ask questions in natural language.
cypher_chain.run(
"How many open tickets there are?"
)
See docs
- Blog: Using a Knowledge Graph to implement a DevOps RAG application
- Blog: Implementing advanced RAG strategies with Neo4j
- Docs: Neo4j DB QA chain
Conclusion
Seamlessly retrieving structured and unstructured data across a variety of data sources is crucial for unlocking the potential of LLMs. We summarize four popular "natural-language-to-structured query" pipelines that have emerged for various types of datastores and provide templates and cookbooks for users to get started.