This blog post walks through our improved regression testing experience in LangSmith. If video form is more your style, you can check out our YouTube walkthrough here. Sign up for LangSmith here for free to try it out for yourself!
The ability to quickly and reliably evaluate your LLM application allows AI engineers to iterate with confidence. Many of the fastest moving and most successful teams we see have efficient testing and experimentation processes. This generally involves (1) setting up a dataset of inputs and (optionally) expected outputs, (2) defining some evaluation criteria. From there, you can evaluate different prompts, models, cognitive architectures, etc.
There are a few key differences between this type of testing and traditional software testing. One main difference: when testing AI applications they may not achieve a perfect score on the evaluation dataset. This is in contrast to software testing where you expect tests to always pass. This difference has two downstream effects. First, it becomes important to track the results of your tests over time. This isn’t necessary in software testing because it’s always 100% passing, but in AI engineering tracking this performance over time is necessary for making sure you’re improving. Second, it’s important to be able to compare the individual datapoints between two (or more) runs. You want to be able to see which datapoints the model used to get correct that it now gets wrong (or vice versa).
One pattern I noticed is that great AI researchers are willing to manually inspect lots of data. And more than that, they build infrastructure that allows them to manually inspect data quickly. Though not glamorous, manually examining data gives valuable intuitions about the problem.
This quote from Jason Wei perfectly describes the importance of looking at data, and the importance of infrastructure that allows them to do that. At LangSmith we strive to build that infrastructure, and it’s led to some big improvements in our regression testing flow.
So what do we think that infrastructure consists of?
First, you need to be able to select multiple experiments to compare. At least two, but it’s often useful to be able to view three or four at the same time. To enable this, we’ve built our Comparison View. This allows you to select any number of runs and open up into a view where you can see all the results at the same time.
Second, you need a lot of control over this comparison view. You may want to view information in different ways depending on what you’re looking for. For example, sometimes you just want a high level overview, other times you want to see all the text, other times you want to see the latency of each call. With our Display options, you can easily select what information you want to see.
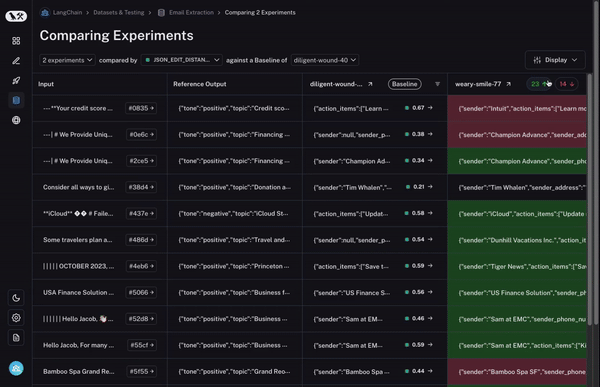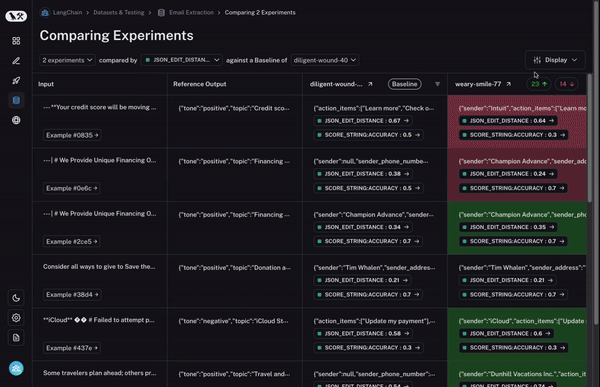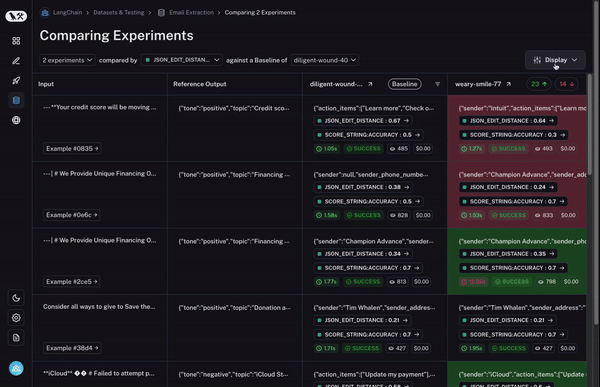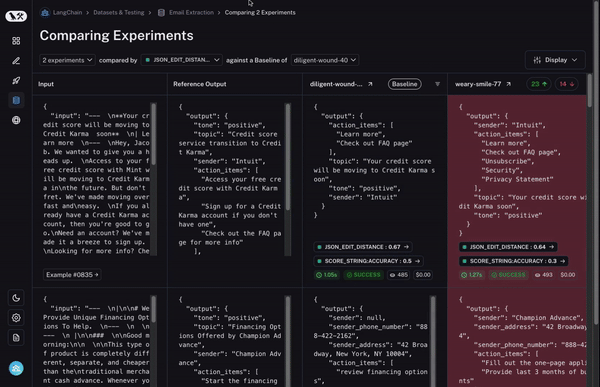
Third - and most importantly - you want to be able to quickly drill into datapoints that behaved different between the two runs. If they behaved differently - there’s something interesting happening there! So how do we enable this?
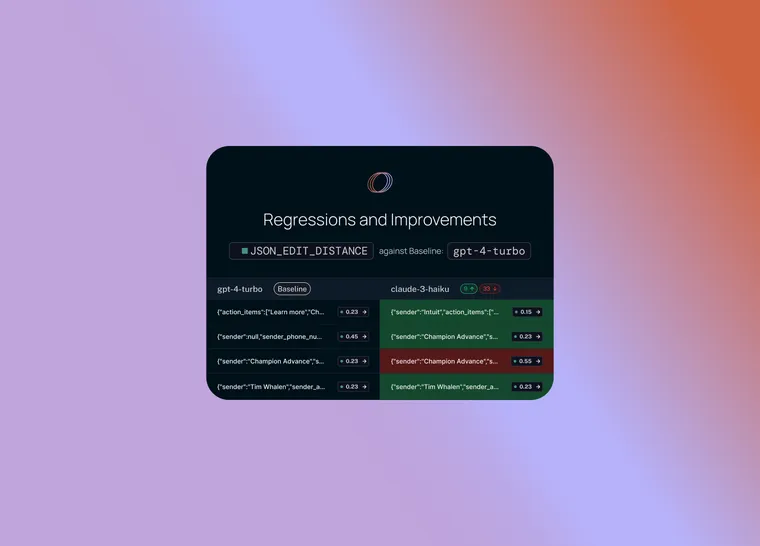
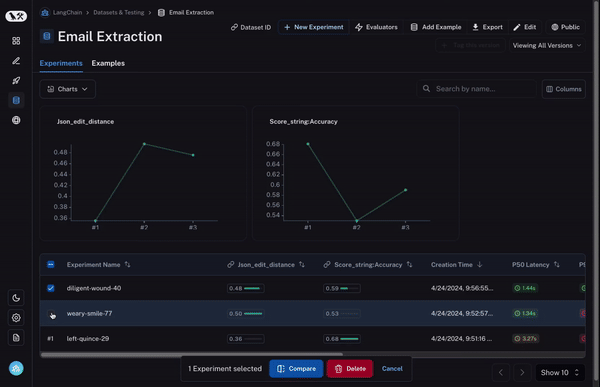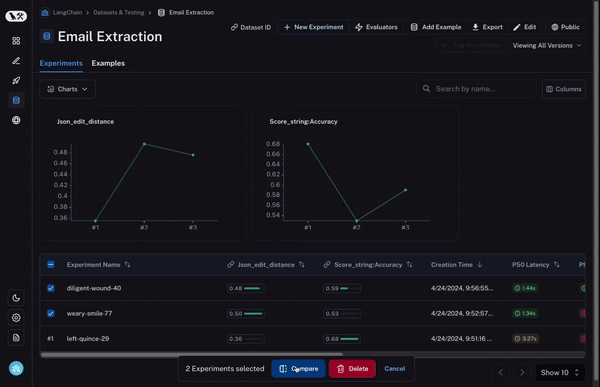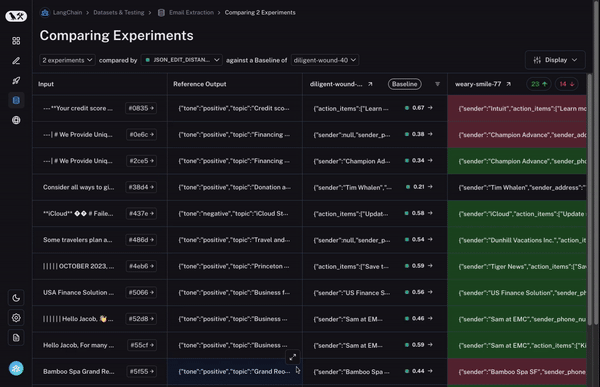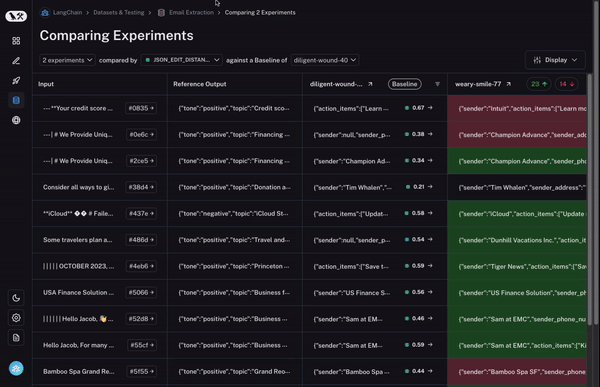
To start, we set a baseline run. We then take one of the evaluation metrics that you calculated and automatically highlight which datapoints increased or decreased on that metric compared to the baseline. This will shade some cells green or red.
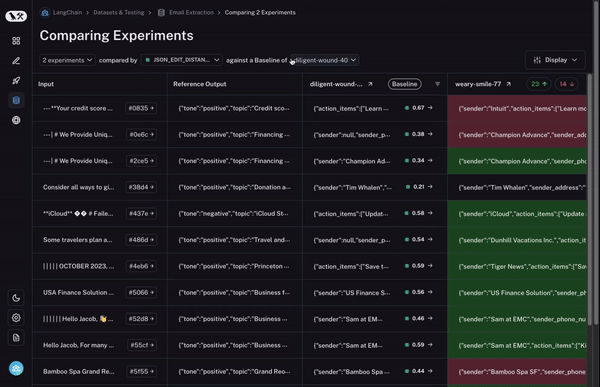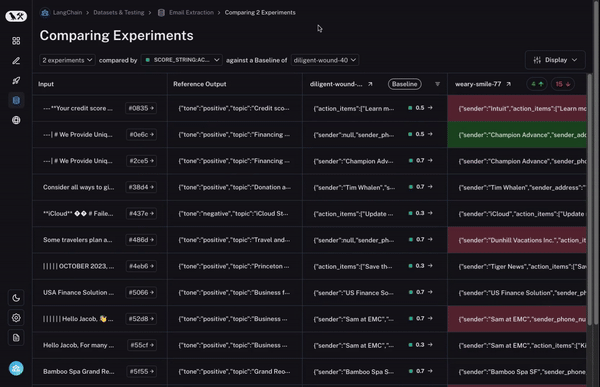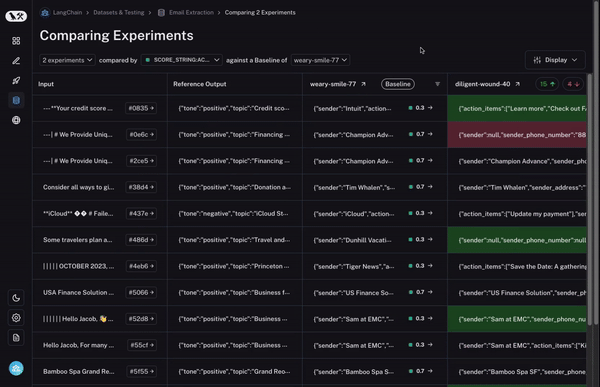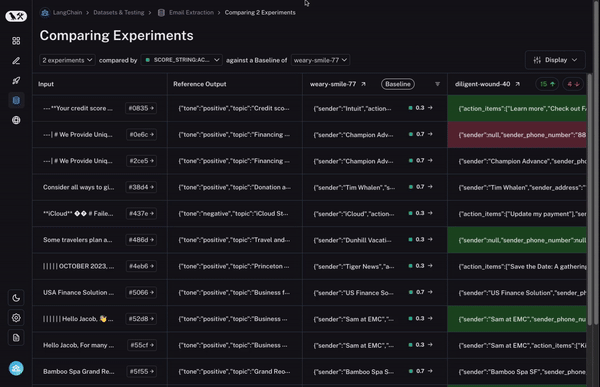
But that’s not all! You can easily filter to only the datapoints that increased/decreased by choosing the toggle at the top of the column. If you have lots of datapoints, this lets you quickly drill in on the most interesting ones.
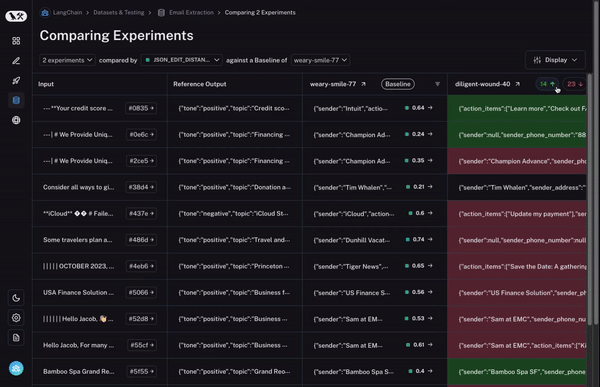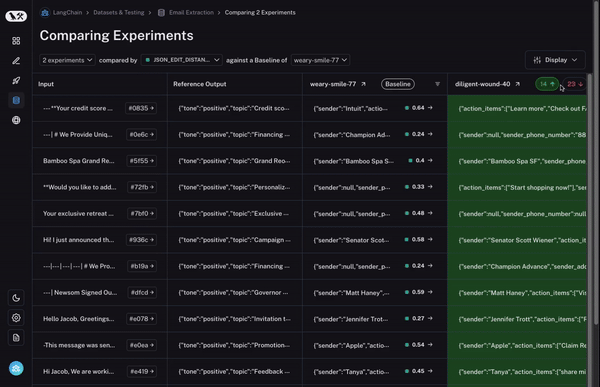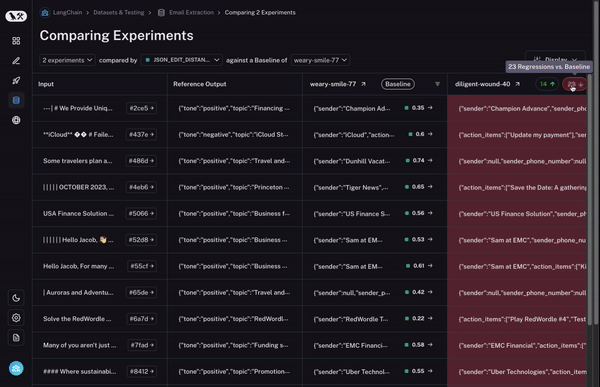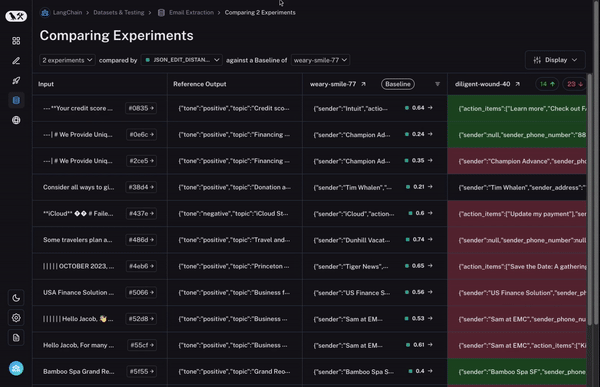
And finally, once you’ve identified a row that you’re interested in, you can easily expand that row to get a more holistic and specific view of just that datapoint and how the different runs performed on it.
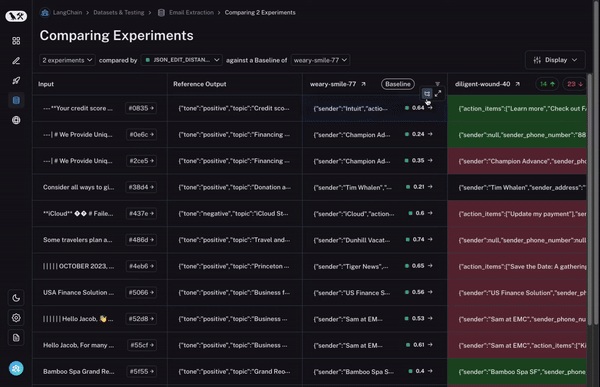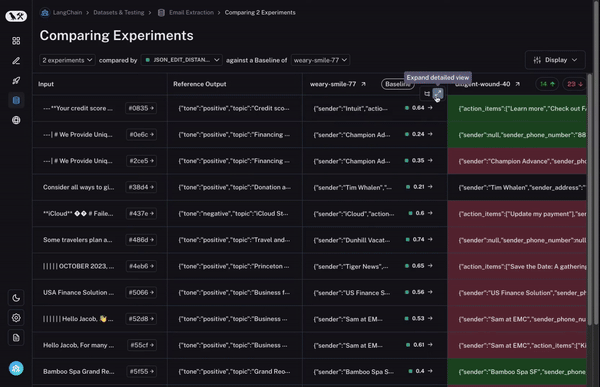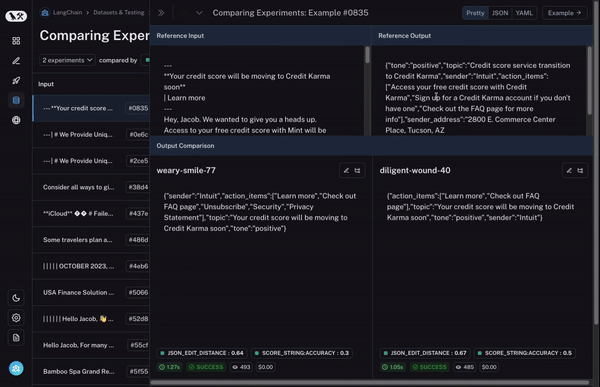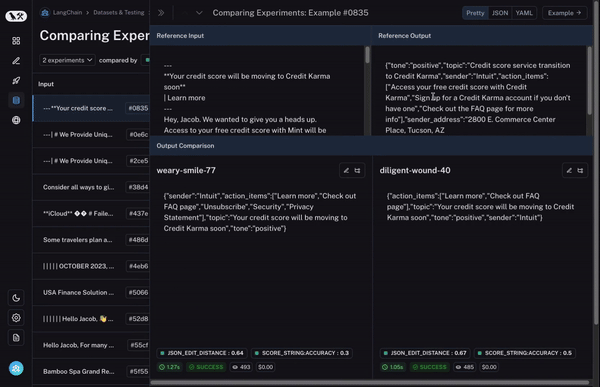
These features make it easy to explore data across multiple evaluation runs. This type of exploration is crucial for being able to quickly iterate. This concept of comparing multiple runs is phenomenon that is different between AI and software testing, and we’ve got a few more features (coming soon!) that make this even easier!
If video form is more your style, you can check out our YouTube walkthrough here. Sign up for LangSmith here for free to try it out for yourself!