Summary
Seamless question-answering across diverse data types (images, text, tables) is one of the holy grails of RAG. We’re releasing three new cookbooks that showcase the multi-vector retriever for RAG on documents that contain a mixture of content types. These cookbooks as also present a few ideas for pairing multimodal LLMs with the multi-vector retriever to unlock RAG on images.
- Cookbook for semi-structured (tables + text) RAG
- Cookbook for multi-modal (text + tables + images) RAG
- Cookbook for private multi-modal (text + tables + images) RAG
Context
LLMs can acquire new information in at least two ways: (1) weight updates (e.g., fine-tuning) and (2) RAG (retrieval augmented generation), which passes relevant context to the LLM via prompt. RAG has particular promise for factual recall because it marries the reasoning capability of LLMs with the content of external data sources, which is particularly powerful for enterprise data.

Ways To Improve RAG
A number of techniques to improve RAG have been developed:
| Idea | Example | Sources |
|---|---|---|
| Base case RAG | Top K retrieval on embedded document chunks, return doc chunks for LLM context window | LangChain vectorstores, embedding models |
| Summary embedding | Top K retrieval on embedded document summaries, but return full doc for LLM context window | LangChain Multi Vector Retriever |
| Windowing | Top K retrieval on embedded chunks or sentences, but return expanded window or full doc | LangChain Parent Document Retriever |
| Metadata filtering | Top K retrieval with chunks filtered by metadata | Self-query retriever |
| Fine-tune RAG embeddings | Fine-tune embedding model on your data | LangChain fine-tuning guide |
| 2-stage RAG | First stage keyword search followed by second stage semantic Top K retrieval | Cohere re-rank |
Applying RAG to Diverse Data Types
Yet, RAG on documents that contain semi-structured data (structured tables with unstructured text) and multiple modalities (images) has remained a challenge. With the emergence of several multimodal models, it is now worth considering unified strategies to enable RAG across modalities and semi-structured data.
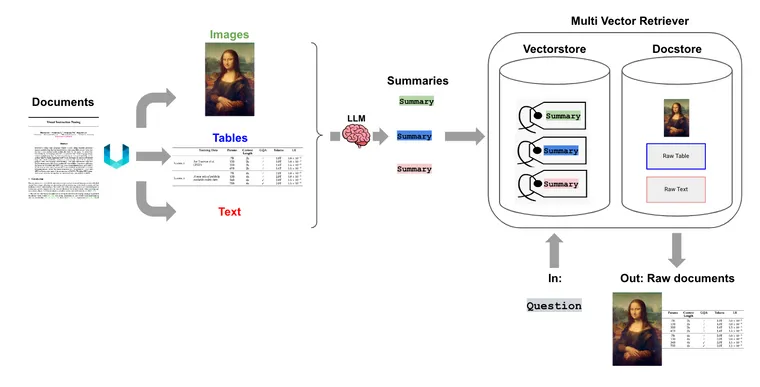
Multi-Vector Retriever
Back in August, we released the multi-vector retriever. It uses a simple, powerful idea for RAG: decouple documents, which we want to use for answer synthesis, from a reference, which we want to use for retriever. As a simple example, we can create a summary of a verbose document optimized to vector-based similarity search, but still pass the full document into the LLM to ensure no context is lost during answer synthesis. Here, we show that this approach useful beyond raw text, and can be applied generally to either tables or images to support RAG.
Document Loading
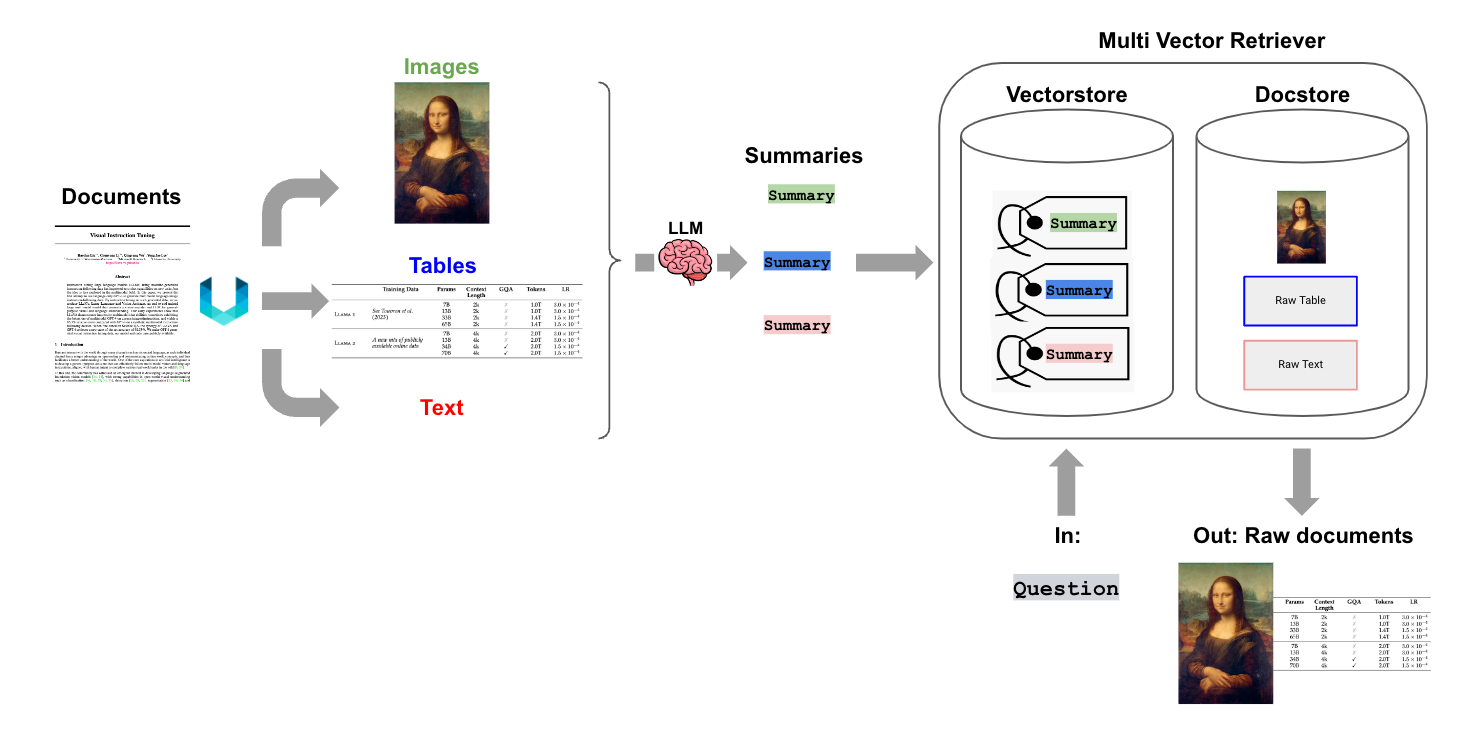
Of course, to enable this approach we first need the ability to partition a document into its various types. Unstructured is a great ELT tool well-suited for this because it can extract elements (tables, images, text) from numerous file types.
For example, Unstructured will partition PDF files by first removing all embedded image blocks. Then it will use a layout model (YOLOX) to get bounding boxes (for tables) as well as titles, which are candidate sub-sections of the document (e.g., Introduction, etc). It will then perform post processing to aggregate text that falls under each title and perform further chunking into text blocks for downstream processing based on user-specific flags (e.g., min chunk size, etc).
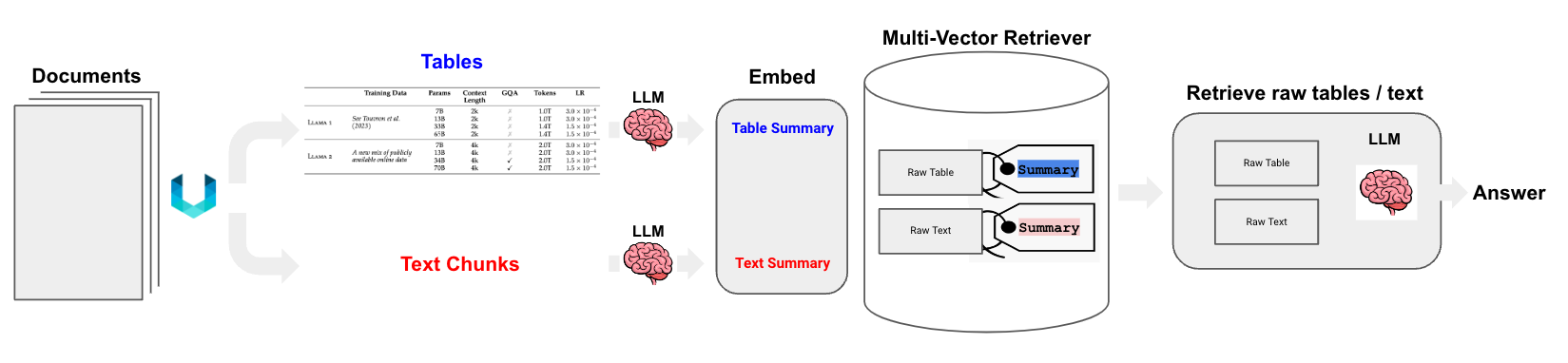
Semi-Structured Data
The combination of Unstructured file parsing and multi-vector retriever can support RAG on semi-structured data, which is a challenge for naive chunking strategies that may spit tables. We generate summaries of table elements, which is better suited to natural language retrieval. If a table summary is retrieved via semantic similarity to a user question, the raw table is passed to the LLM for answer synthesis as described above. See the below cookbook and diagram:
Multi-Modal Data
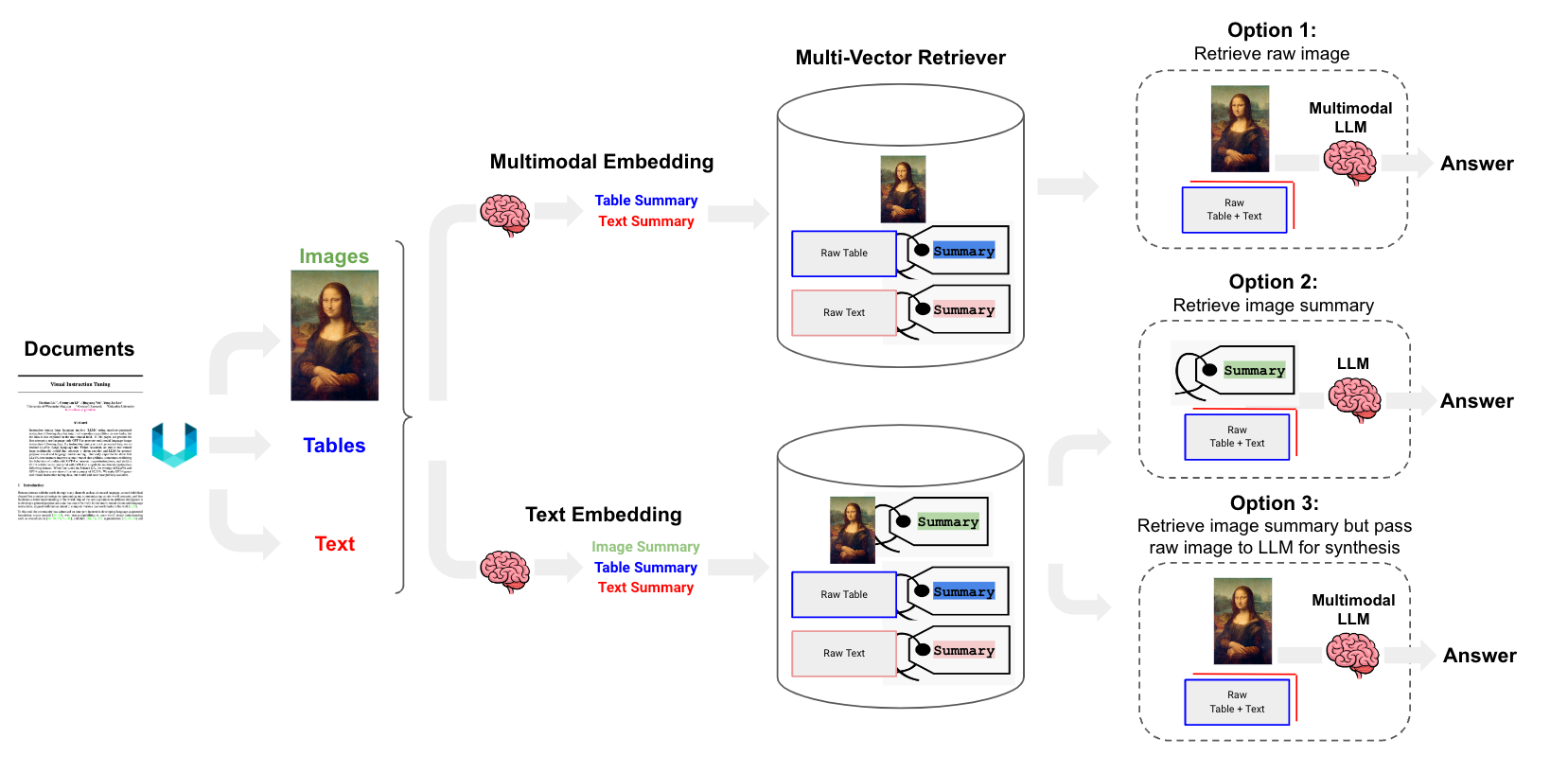
We can take this one step further and consider images, which is quickly becoming enabled by the release of multi-modal LLMs such as GPT4-V and open source models such as LLaVA and Fuyu-8b. There are at least three ways to approach the problem, which utilize the multi-vector retriever framework as discussed above:
Option 1: Use multimodal embeddings (such as CLIP) to embed images and text together. Retrieve either using similarity search, but simply link to images in a docstore. Pass raw images and text chunks to a multimodal LLM for synthesis.
Option 2: Use a multimodal LLM (such as GPT4-V, LLaVA, or FUYU-8b) to produce text summaries from images. Embed and retrieve text summaries using a text embedding model. And, again, reference raw text chunks or tables from a docstore for answer synthesis by a LLM; in this case, we exclude images from the docstore (e.g., because can't feasibility use a multi-modal LLM for synthesis).
Option 3: Use a multimodal LLM (such as GPT4-V, LLaVA, or FUYU-8b) to produce text summaries from images. Embed and retrieve image summaries with a reference to the raw image, as we did above in option 1. And, again, pass raw images and text chunks to a multimodal LLM for answer synthesis. This option is sensible if we don't want to use multimodal embeddings.
We tested option 2 using the 7b parameter LLaVA model (weights available here) to generate image image summaries. LLaVA recently added to llama.cpp, which allows it run on consumer laptops (Mac M2 max, 32gb ~45 token / sec) and produces reasonable image summaries. For example, for the image below it captures the humor: The image features a close-up of a tray filled with various pieces of fried chicken. The chicken pieces are arranged in a way that resembles a map of the world, with some pieces placed in the shape of continents and others as countries. The arrangement of the chicken pieces creates a visually appealing and playful representation of the world.

We store these in the multi-vector retriever along with table and text summaries.
If data privacy is a concern, this RAG pipeline can be run locally using open source components on a consumer laptop with LLaVA 7b for image summarization, Chroma vectorstore, open source embeddings (Nomic’s GPT4All), the multi-vector retriever, and LLaMA2-13b-chat via Ollama.ai for answer generation.
Conclusion
We show that the multi-vector retriever can be used to support semi-structured RAG as well as semi-structured RAG with multi-modal data. We also show that this full pipeline can be run locally on a consumer laptops using open source components. Finally, we present three general approaches for multimodal RAG that utilize the multi-vector retriever concept to be features in future cookbooks.