One pattern I noticed is that great AI researchers are willing to manually inspect lots of data. And more than that, they build infrastructure that allows them to manually inspect data quickly. Though not glamorous, manually examining data gives valuable intuitions about the problem.
- Jason Wei, OpenAI
Evaluations continue to be one of the hardest parts of building LLM applications. It's really tough to evaluate in a quantitative way the effect of changes to your prompt, chain, or agent. We're bullish on LLM-assisted evaluation, but, at the same time, we definitely recognize that it's hard to have complete trust in them.
Jason's tweet above sums up what we see a lot of the best researchers (and engineers) doing. They want to manually inspect data to gain intuition about the problem. At LangChain, we want to build the infrastructure to help do that - which is why we're excited to announce Test Run Comparisons today.
In the initial release of LangSmith we had support for running tests, including scoring them with LLM-assisted feedback. However, each test was run in isolation. We quickly saw two usage patterns emerge:
- People are still hesitant to trust the LLM-assisted feedback directly
- Users often wanted to not only score their test run in isolation, but also compare it to previous iterations
When building Test Run Comparisons, we kept both of these insights in mind. We wanted to create an easy UX to see multiple test runs side-by-side. We also wanted to create an easy UX where people could use LLM-assisted evals (or regex/other eval) to get an initial score, then manually explore those datapoints for further insights.
So how does it work?
First, you need to set up a dataset and run some tests. See documentation here for instructions on how to do that. Nothing new here, so if you've already done that for an existing project you're all good.
Inside a dataset, you can easily select two (or more) test runs, then click Compare.

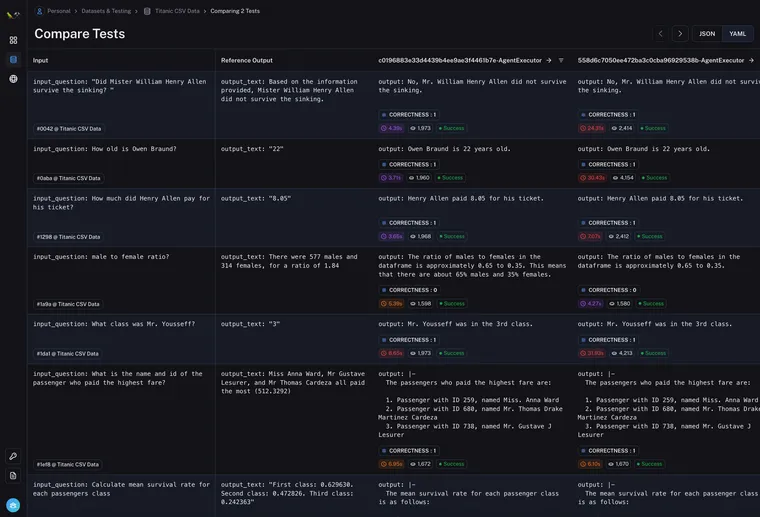
From there, you will be brought into the Test Run Comparison view. This should look like the below

You can easily see the inputs, the reference output, and then the actual output for each datapoint - along with any eval metrics, time and latency for that run.
This view is designed to make it easy to quickly compare test runs across the same inputs. If you want a deeper look at a particular datapoint, you can click on that row and sidebar will pop up allowing you to drill down into the details of those runs.

On that sidebar, we've also added up and down carets (▲ and ▼) to easily flip between runs.
This view should hopefully make it easy to compare runs for a particular datapoint. But how do you know what datapoints to be looking at?
We've added filters for each column - similar to Excel. Using these filters, you can filter the rows according to any criteria.

Building an LLM application is hard. A big part of that is understanding how the LLM is working on a particular task. Setting up an evaluation dataset and then being able to easily compare runs on that dataset is crucial for developing the understanding needed to improve the application. Test Run Comparison in LangSmith aimed at solving this problem. Please let us know any feedback you have!
LangSmith is in private beta - sign up here. We'll be rolling out more access over the next few weeks, as well as continuing to add features like this.