
Editor's Note: This post was written in collaboration with the Neo4J team.
RAG applications are all the rage at the moment. Everyone is building their company documentation chatbot or similar. Mostly, they all have in common that their source of knowledge is unstructured text, which gets chunked and embedded in one way or another. However, not all information arrives as unstructured text.
Say, for example, you wanted to create a chatbot that could answer questions about your microservice architecture, ongoing tasks, and more. Tasks are mostly defined as unstructured text, so there wouldn’t be anything different from the usual RAG workflow there. However, how could you prepare information about your microservices architecture so the chatbot can retrieve up-to-date information? One option would be to create daily snapshots of the architecture and transform them into text that the LLM would understand. However, what if there is a better approach? Meet knowledge graphs, which can store both structured and unstructured information in a single database.
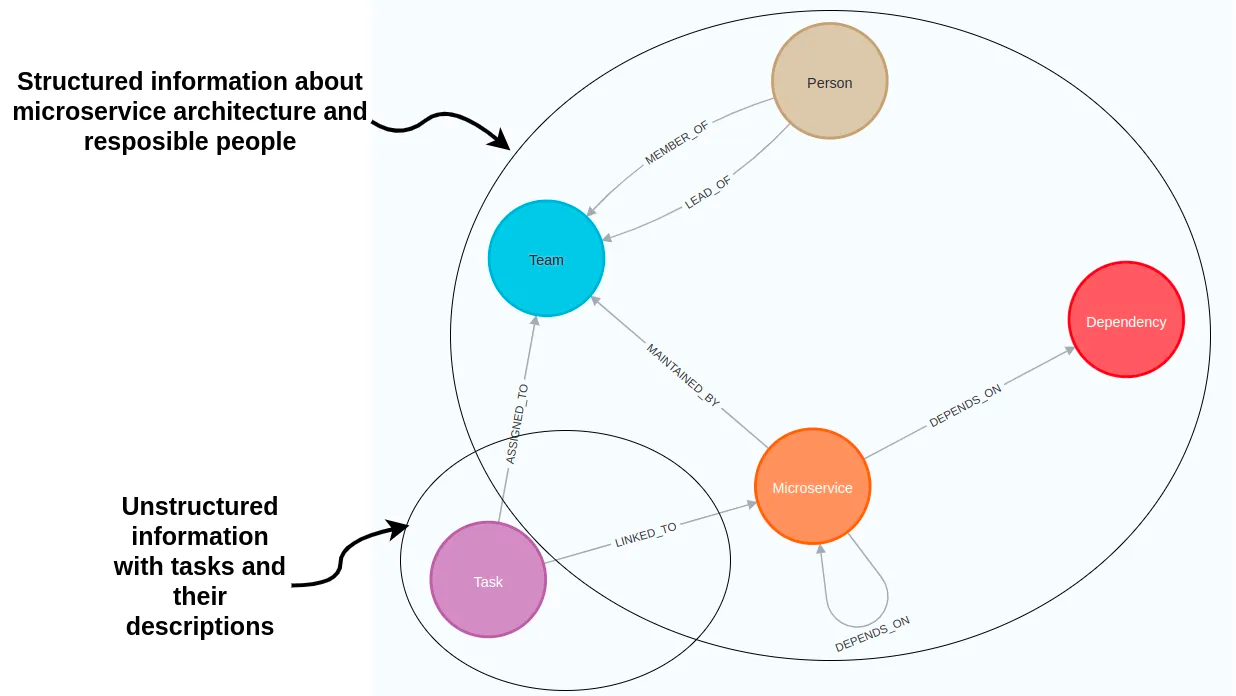
Nodes and relationships are used to describe data in a knowledge graph. Typically, nodes are used to represent entities or concepts like people, organizations, and locations. In the microservice graph example, nodes describe people, teams, microservices, and tasks. On the other hand, relationships are used to define connections between these entities, like dependencies between microservices or task owners.
Both nodes and relationships can have property values stored as key-value pairs.
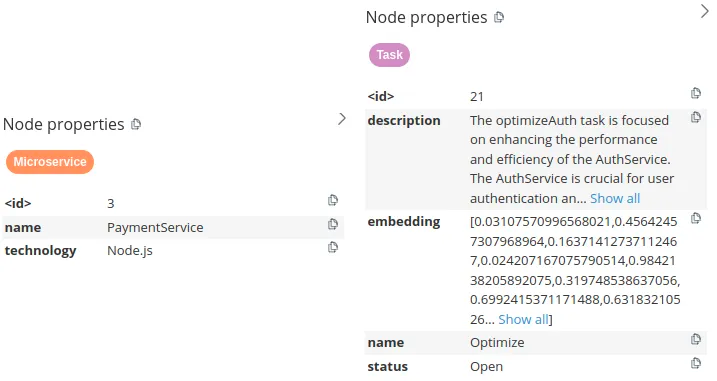
The microservice nodes have two node properties describing their name and technology. On the other hand, task nodes are more complex. They have the the name, status, description, as well as embedding properties. By storing text embedding values as node properties, you can perform a vector similarity search of task descriptions identical to if you had the tasks stored in a vector database. Therefore, knowledge graphs allow you to store and retrieve both structured and unstructured information to power your RAG applications.
In this blog post, I’ll walk you through a scenario of implementing a knowledge graph based RAG application with LangChain to support your DevOps team. The code is available on GitHub.
Neo4j Environment Setup
You need to set up a Neo4j 5.11 or greater to follow along with the examples in this blog post. The easiest way is to start a free instance on Neo4j Aura, which offers cloud instances of Neo4j database. Alternatively, you can also set up a local instance of the Neo4j database by downloading the Neo4j Desktop application and creating a local database instance.from langchain.graphs import Neo4jGraph.
from langchain.graphs import Neo4jGraph
url = "neo4j+s://databases.neo4j.io"
username ="neo4j"
password = ""
graph = Neo4jGraph(
url=url,
username=username,
password=password
)Dataset
Knowledge graphs are excellent at connecting information from multiple data sources. You could fetch information from cloud services, task management tools, and more when developing a DevOps RAG application.
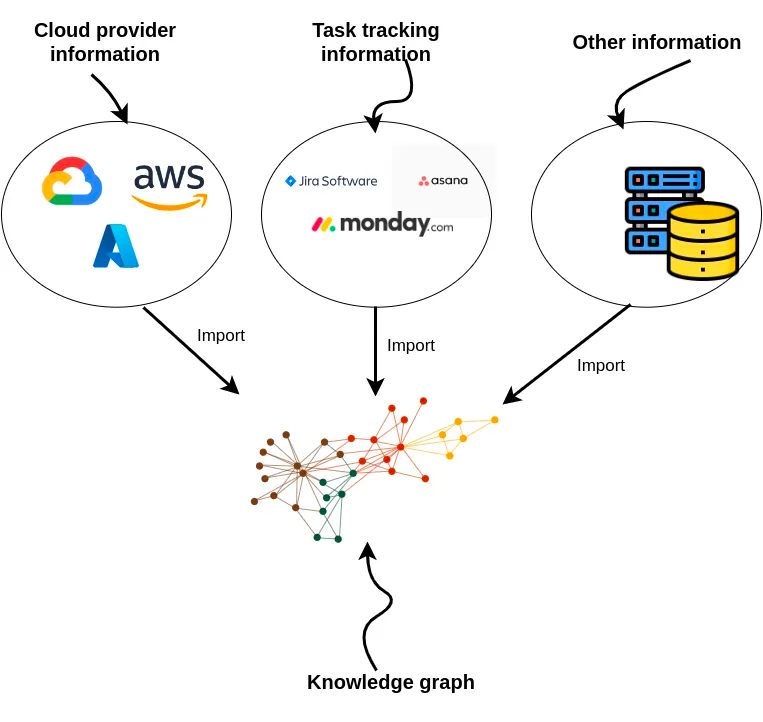
import requests
url = "https://gist.githubusercontent.com/tomasonjo/08dc8ba0e19d592c4c3cde40dd6abcc3/raw/da8882249af3e819a80debf3160ebbb3513ee962/microservices.json"
import_query = requests.get(url).json()['query']
graph.query(
import_query
)
If you inspect the graph in Neo4j Browser, you should get a similar visualization.
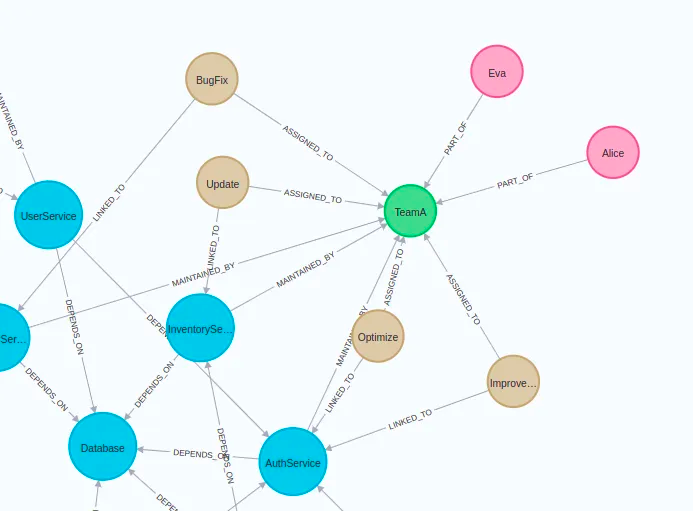
Blue nodes describe microservices. These microservices may have dependencies on one another, implying that the functioning or the outcome of one might be reliant on another’s operation. On the other hand, the brown nodes represent tasks that are directly linked to these microservices. Besides showing how things are set up and their linked tasks, our graph also shows which teams are in charge of what.
Neo4j Vector index
We will begin by implementing a vector index search for finding relevant tasks by their name and description. If you are unfamiliar with vector similarity search, let me give you a quick refresher. The key idea is to calculate the text embedding values for each task based on their description and name. Then, at query time, find the most similar tasks to the user input using a similarity metric like a cosine distance.
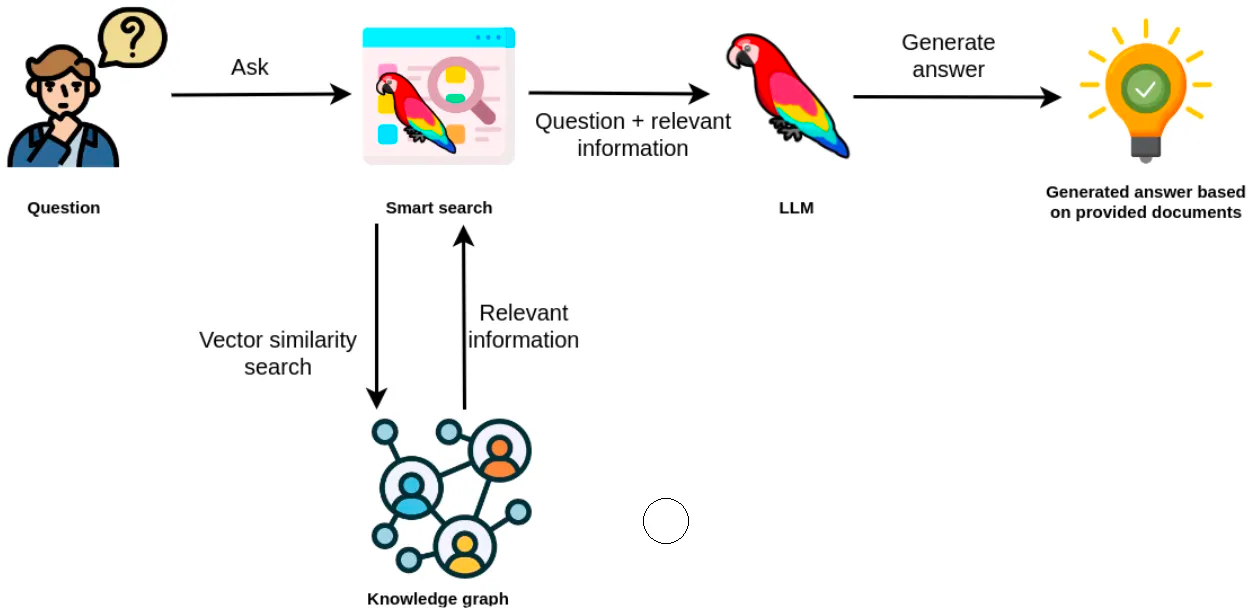
The retrieved information from the vector index can then be used as context to the LLM so it can generate accurate and up-to-date answers.
The tasks are already in our knowledge graph. However, we need to calculate the embedding values and create the vector index. This can be achieved with the from_existing_graph method.
import os
from langchain.vectorstores.neo4j_vector import Neo4jVector
from langchain.embeddings.openai import OpenAIEmbeddings
os.environ['OPENAI_API_KEY'] = "OPENAI_API_KEY"
vector_index = Neo4jVector.from_existing_graph(
OpenAIEmbeddings(),
url=url,
username=username,
password=password,
index_name='tasks',
node_label="Task",
text_node_properties=['name', 'description', 'status'],
embedding_node_property='embedding',
)In this example, we used the following graph-specific parameters for the from_existing_graph method.
- index_name: name of the vector index
- node_label: node label of relevant nodes
- text_node_properties: properties to be used to calculate embeddings and retrieve from the vector index
- embedding_node_property: which property to store the embedding values to
Now that the vector index has been initiated, we can use it as any other vector index in LangChain.
response = vector_index.similarity_search(
"How will RecommendationService be updated?"
)
print(response[0].page_content)
# name: BugFix
# description: Add a new feature to RecommendationService to provide ...
# status: In ProgressYou can observe that we construct a response of a map or dictionary-like string with defined properties in the text_node_properties parameter.
Now we can easily create a chatbot response by wrapping the vector index into a RetrievalQA module.
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
vector_qa = RetrievalQA.from_chain_type(
llm=ChatOpenAI(),
chain_type="stuff",
retriever=vector_index.as_retriever()
)
vector_qa.run(
"How will recommendation service be updated?"
)
# The RecommendationService is currently being updated to include a new feature
# that will provide more personalized and accurate product recommendations to
# users. This update involves leveraging user behavior and preference data to
# enhance the recommendation algorithm. The status of this update is currently
# in progress.
One limitation of vector indexes, in general, is that they don’t provide the ability to aggregate information like you would with a structured query language like Cypher. Take, for example, the following example:
vector_qa.run(
"How many open tickets there are?"
)
# There are 4 open tickets.
The response seems valid, and the LLM uses assertive language, making you believe the result is correct. However, the problem is that the response directly correlates to the number of retrieved documents from the vector index, which is four by default. What actually happens is that the vector index retrieves four open tickets, and the LLM unquestioningly believes that those are all the open tickets. However, the truth is different, and we can validate it using a Cypher statement.
graph.query(
"MATCH (t:Task {status:'Open'}) RETURN count(*)"
)
# [{'count(*)': 5}]There are five open tasks in our toy graph. While vector similarity search is excellent for sifting through relevant information in unstructured text, it lacks the capability to analyze and aggregate structured information. Using Neo4j, this problem can be easily solved by employing Cypher, which is a structured query language for graph databases.
Graph Cypher search
Cypher is a structured query language designed to interact with graph databases and provides a visual way of matching patterns and relationships. It relies on the following ascii-art type of syntax:
(:Person {name:"Tomaz"})-[:LIVES_IN]->(:Country {name:"Slovenia"})
This patterns describes a node with a label Person and the name property Tomaz that has a LIVES_IN relationship to the Country node of Slovenia.
The neat thing about LangChain is that it provides a GraphCypherQAChain, which generates the Cypher queries for you, so you don’t have to learn Cypher syntax in order to retrieve information from a graph database like Neo4j.
The following code will refresh the graph schema and instantiate the Cypher chain.
from langchain.chains import GraphCypherQAChain
graph.refresh_schema()
cypher_chain = GraphCypherQAChain.from_llm(
cypher_llm = ChatOpenAI(temperature=0, model_name='gpt-4'),
qa_llm = ChatOpenAI(temperature=0), graph=graph, verbose=True,
)Generating valid Cypher statements is a complex task. Therefore, it is recommended to use state-of-the-art LLMs like gpt-4 to generate Cypher statements, while generating answers using the database context can be left to gpt-3.5-turbo.
Now, you can ask the same question about how many tickets are open.
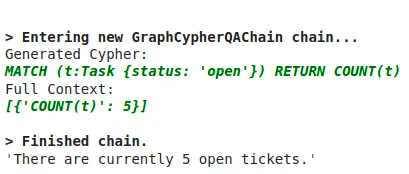
cypher_chain.run(
"How many open tickets there are?"
)Result is the following
You can also ask the chain to aggregate the data using various grouping keys, like the following example.
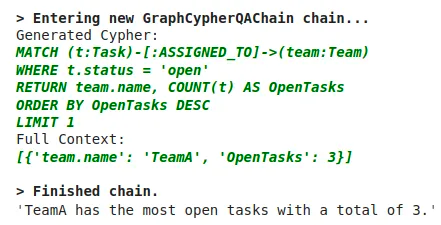
cypher_chain.run(
"Which team has the most open tasks?"
)Result is the following
You might say these aggregations are not graph-based operations, and you will be correct. We can, of course, perform more graph-based operations like traversing the dependency graph of microservices.
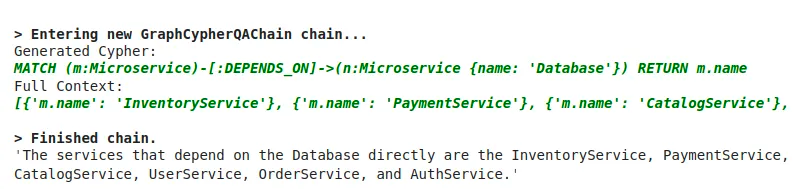
cypher_chain.run(
"Which services depend on Database directly?"
)Result is the following
Of course, you can also ask the chain to produce variable-length path traversals by asking questions like:
cypher_chain.run(
"Which services depend on Database indirectly?"
)
Some of the mentioned services are the same as in the directly dependent question. The reason is the structure of the dependency graph and not the invalid Cypher statement.
Knowledge graph agent
Since we have implemented separate tools for the structured and unstructured parts of the knowledge graph, we can add an agent that can use these two tools to explore the knowledge graph.
from langchain.agents import initialize_agent, Tool
from langchain.agents import AgentType
tools = [
Tool(
name="Tasks",
func=vector_qa.run,
description="""Useful when you need to answer questions about descriptions of tasks.
Not useful for counting the number of tasks.
Use full question as input.
""",
),
Tool(
name="Graph",
func=cypher_chain.run,
description="""Useful when you need to answer questions about microservices,
their dependencies or assigned people. Also useful for any sort of
aggregation like counting the number of tasks, etc.
Use full question as input.
""",
),
]
mrkl = initialize_agent(
tools,
ChatOpenAI(temperature=0, model_name='gpt-4'),
agent=AgentType.OPENAI_FUNCTIONS, verbose=True
)Let’s try out how well does the agent works.
response = mrkl.run("Which team is assigned to maintain PaymentService?")
print(response)Result is the following
Let’s now try to invoke the Tasks tool.
response = mrkl.run("Which tasks have optimization in their description?")
print(response)Result is the following

One thing is certain. I have to work on my agent prompt engineering skills. There is definitely room for improvement in tools description. Additionally, you can also customize the agent prompt.
Conclusion
Knowledge graphs are an excellent fit when you require structured and unstructured data to power your RAG applications. With the approach shown in this blog post, you can avoid polyglot architectures, where you must maintain and sync multiple types of databases. Learn more about graph-based search in LangChain here.
The code is available on GitHub.
If you are eager to learn more about building AI applications with graphs, join us at the NODES, online, 24h conference organized by Neo4j on October 26th, 2023.