
Editor's Note: the following is a guest blog post from our friends at You.com. We've seen a lot of interesting use cases around interacting with the internet, and we're always looking for new tools to highlight to our community that can help do that. So when You.com mentioned they would releasing an API access to their search engine - the same one they use to power their AI assistant - we jumped at the opportunity to help them highlight this.
This blog post walks through some results highlighting the efficacy of the You.com search API. These results are based off of the below notebook, so you can follow along there:
YouRetriever
We are excited to announce the release of YouRetriever, the easiest way to get access to the You.com Search API. The You.com Search API is designed by LLMs for LLMs with an emphasis on Retrieval Augmented Generation (RAG) applications. We evaluate our API on a number of datasets to benchmark performance of LLMs in the RAG-QA setting and use these benchmarks to guide the optimization of our search systems.
In this blog post we will compare and contrast the You.com Search API with the Google Search API as well as give the reader the tools to evaluate LLMs in the RAG-QA setting. We will evaluate our retriever performance on Hotpot QA using the RetrievalQA Chain. Hotpot is a dataset which is comprised of a question, answer, and context. The context can vary in relevance to the question/answer with a special "distractor" setting where the LLM needs to not be distracted by certain misleading text within the context. In this experiment we will be removing the context from the dataset and replacing it with text snippets which come back from the search APIs. In this sense the entire internet is the distractor text since the APIs are responsible for finding the answer to the question across the entire internet not just within the list of snippets supplied in the dataset. We call this the "web distractor" setting for evaluating search APIs with respect to their performance being used in conjunction with an LLM.
Retrieval
The first thing you will notice about our text snippets is that we provide larger text snippets when we can and will soon have the option for specifying the amount of text you want returned from a single snippet to the entire page. Let's ask it about the greatest pinball player ever, Keith Elwin.

You can see that even with the default settings we return 27 text snippets about the great Keith and some of the documents contain a decent amount of text. This makes our search API especially powerful for LLMs operating in the RAG-QA setting.
However, these 27 text snippets can be a lot for a language model to work with. We can use the models with longer context windows as one workaround. There are a few options you can employ here if you don't want to use a smaller context window model. The first is the cap the number of documents you feed from our API to the LLM. The other option is to use the map_reduce chain type. The map_reduce chain type takes larger chunks of text and breaks them down to make them digestible by the LLM. This does mean that you will need to make multiple calls to the LLM which will mean slower run-time but you'll be able to process all the data returned from the YouRetriever.
Evaluation
In order to evaluate, we'll use the HotPotQA dataset. We load this up from the Huggingface dataset using the datasets library. We use the fullwiki setting here instead of the distractor but as we said before, we'll be using our own context powered by the search APIs instead of what comes off the shelf.
Let's take a sample from Hotpot QA and compare our search API with one of the current alternatives in LangChain, the GoogleSearchAPIWrapper. This isn't a retriever in LangChain but it only takes a small amount of code to make an analog retriever. All we need to do is implement the _get_relevant_documents method of the abstract base class BaseRetriever. We should note here, that you could easily repeat this experiment and swap in another web search API like Bing. First let's create a small utility for the existing wrapper.

As you can see Google gives us much less information to feed into our LLM. While in both cases we requested results from 10 web results, the You.com Search API will attempt to give multiple text snippets per web result. To further demonstrate, we can now get predictions from the exact same LLM so we do our best to isolate the experiment to evaluating the search APIs.
Now we can use these two search methods and get predictions from the LLM using each search API's results. It's important to remember that at this point we have done everything we can to ensure the only thing we're testing is the quality of search results for use by an LLM to answer these questions.
We use the F1 score function from the hotpot repository to ensure we are as close to the evaluation setting that was presented in the paper.
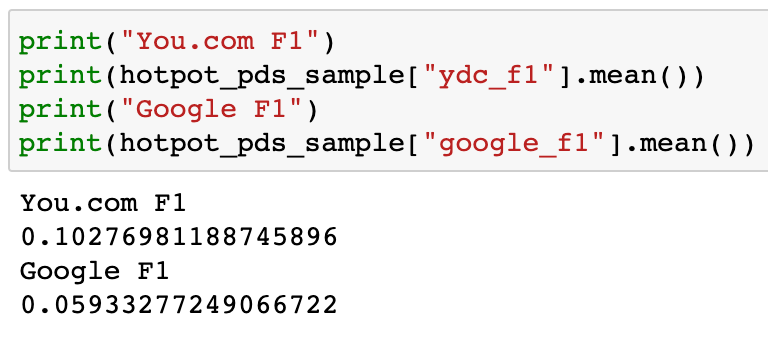
On the sample of data that we run over, we get the following results:
In Conclusion
As you can see, the You.com Search API heavily out-performs Google on this small subset of data. Please stay tuned as You.com will be releasing a much larger search study in the weeks to come. If you would like to be an early access partner of ours please email api@you.com with your background, use case, and expected daily call volume.